논문 주소: https://arxiv.org/pdf/2601.16065v1
project: https://anonymous.4open.science/r/CBD3
ABSTRACT
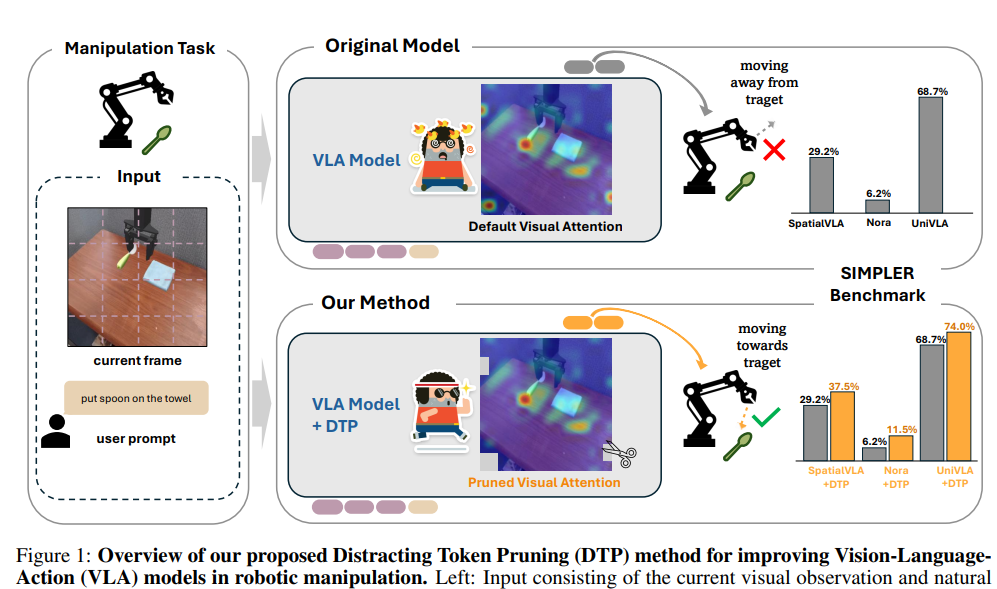
Vision Language Action model은 환경을 이해하고 액션을 직접 출력하기 위해 VLMs의 강력한 인지 능력을 활용함으로써 robotic manipulation 분야에서 눈부신 발전을 보여주었습니다. 그러나 기본적으로 VLA 몯레은 task와 무관한 영역의 이미지 token에 과도하게 주의를 기울일 수 있으며 본 연구에서는 이를 distraction tokens이라고 정의합니다. 이러한 동작은 매 단계에서 원하는 액션 토큰의 생성을 방해하며 task의 성공률의 영향을 미칠 수 있습니다.
본 논문에서는 이러한 distracting image tokens를 동적으로 감지하고 제거하는 간단하면서도 효과적인 plug-and-play 방식의 Distracting Token Pruning (DTP) 프레임워크를 소개합니다. 원래의 Architecture를 변경하거나 추가 입력을 더하지 않고도, 모델의 visual attention patterns를 교정함으로써 태스크 성공률을 개선하고 모델의 성능 상한선을 탐색하는 것을 목표로 합니다.
SIMPLER Benchmark에서의 실험 결과, 방법은 서로 다른 유형의 최신 VLA 모델들 전반에서 태스크 성공률의 상대적 향상을 일관되게 달성하며, transformer-based VLAs에 대한 일반화 가능성을 입증했습니다. 추가 분석을 통해 테스트된 모든 모델에서 태스크 성공률과 태스크 무관 영역에 대한 attentions 양 사이에 negative correlation이 있음을 밝혀졌으며, 이는 향후 연구를 가이드할 수 있는 VLA 모델의 공통된 현상을 강조합니다.
1 INTRODUCTION
시각적 콘텐츠를 이해하고 추론하는 데 있어 Vision-Language Models의 성공은 embodied AI를 위한 새로운 가능성을 열어주었습니다. 대규모 이미지-텍스트 데이터로 학습된 VLMs는 시각적 인식, 추론, 그리고 visual question answering에 탁월합니다. 이를 바탕으로, Vision-Language-Action모델은 VLMs를 확장하여 실행 가능한 로봇 액션을 생성함으로써 고수준의 의미론적 추론과 저수준 제어 사이를 연결합니다. RT-1 및 RT-2와 같은 초기 VLAs는 로봇 제어를 위한 action tokenization을 개척했으며, 이후 OpenVLA와 같은 모델들은 더 작은 크기에도 불구하고 강력한 성능을 달성했습니다. 이러한 진보는 visual encoder, language model, 그리고 이산적인 action token 생성이라는 핵심 VLA 파이프라인을 확립했습니다.
최근의 연구들은 VLA의 능력을 더욱 향상시키고 있습니다. SpatialVLA 등은 더 나은 3D 이해를 위해 depth 정보를 통합하며, Nora는 정밀한 연속 제어를 위해 FAST와 같은 토큰나이저를 채택하고, world-model 접근 방식은 액션 예측을 위해 dynamics modeling을 활용합니다. 이러한 아키텍처적 발전에도 불구하고, VLAs는 여전히 중복된 visual tokens로 인해 조작 태스크에서 실패할 수 있으며, 태스크와 무관한 visual tokens가 cross-attention 중에 불균형하게 높은 attention을 받아 모델이 태스크 관련 영역으로부터 주의가 분산될 수 있습니다(그림 1). 이는 다음과 같은 우려를 낳습니다: Distracting tokens가 태스크 성공에 영향을 미치는가, 그리고 이를 pruning하는 것이 성능을 개선할 수 있는가?
처음의 visual attention patterns를 수동으로 검사하고 모델을 위해 이미지 token을 pruning하는 시도를 진행했습니다. 그러나 이 접근 방식엔 두 가지 주요 한계가 존재합니다. (1) 각 에피소드마다 모델이 수백에서 수천 개의 action tokens를 출력할 수 있기 때문에, 사람이 각 action token에 대한 attention을 검토하는 것은 매우 시간이 많이 걸리며 전체 테스트 수트 분석을 불가능하게 만듭니다. (2) "좋은" attention patterns에 대한 인간의 직관이 모델의 선호도와 일치하지 않을 수 있습니다. 이상적인 attention은 태스크 관련 객체와 영역에 집중해야 하지만, 서로 다른 VLA 모델들은 각자만의 시각적 패턴 선호도를 가질 수 있으므로 수동 pruning이 반드시 성능 향상으로 이어지지는 않습니다.
이러한 두 가지 문제를 해결하기 위해, 본 연구에서는 distracting tokens를 동적으로 pruning하는 plug-and-play 프레임워크인 Distracting Token Pruning (DTP)를 제안합니다. DTP는 세 단계로 구성됩니다: (1) prompt-image token 상호작용이 태스크 관련 visual tokens를 식별하는 Relevance-based important region construction, (2) 각 액션 생성 단계에서 모델이 어떤 이미지 토큰에 집중하는지 attention heatmap을 통해 드러내는 Action attention analysis, (3) 그리고 중요하지 않은 영역(unimportant region)의 attention이 중요 영역 내의 최대 attention을 초과할 경우(허용 오차 $\tau$로 스케일링됨), 해당 visual tokens를 선택적으로 제거하는 intersection-based strategy를 적용합니다. SIMPLER Benchmark에서의 실험은 DTP가 시각적 attention patterns를 효과적으로 교정하고, 태스크 성공률을 높이며, transformer-based VLAs 전반에 걸쳐 일반화됨을 입증합니다.
요약하자면, 본 연구의 작업은 다음과 같은 기여를 합니다: (1) VLA 모델의 공통적인 attention 약점을 해결함으로써 자동으로 distracting tokens를 식별하고 제거하여 태스크 성공률을 높이는 새로운 intersection-based 방법인 Distracting Token Pruning (DTP) 프레임워크를 도입합니다. (2) 허용 오차 $\tau$를 변화시키며 모델 선호도와 일치하고 성능을 극대화하는 이상적인 시각적 attention patterns를 모색함으로써 VLAs의 성능 상한선을 탐구합니다. (3) 중요하지 않은 영역의 attention 값을 분석하여 태스크 성공률과의 음의 상관관계를 밝히고, 더 견고한 VLAs 구축을 위한 통찰을 제공합니다.
2. RELATED WORK
Vision-Language Models (VLMs)는 시각적 이해, 캡셔닝, visual question answering 전반에서 강력한 일반화 성능을 보여주며 멀티모달 추론의 토대가 되었습니다. 인터넷 규모의 이미지-텍스트 데이터에 대한 대규모 사전 학습은 PrismaticVLM, InternVL2.5, PaliGemma 2, Qwen2.5-VL과 같은 모델들이 다양한 시각-언어 태스크에서 인상적인 성능을 달성할 수 있게 했습니다. 이 모델들은 SigLIP 및 DINOv2와 같은 고성능 visual encoders를 LLM과 결합하여, 광범위한 태스크에 적응할 수 있는 유연한 표현을 생성합니다. 주로 정적인 시각-언어 태스크를 위해 설계되었지만, 구조화된 추론에서의 VLMs의 성공은 embodied AI 도메인으로의 확장에 영감을 주었습니다. 특히, 자연어를 지각적 입력과 결합하는 능력은 로봇 제어를 위한 자연스러운 인터페이스를 제공합니다. 그러나 이러한 전환은 고수준의 의미론적 이해뿐만 아니라 지시문과 관측치를 temporally grounded motor actions으로 매핑하는 능력을 요구하며, 이러한 간극이 Vision-Language-Action (VLA) 모델의 등장을 이끌었습니다.
Vision-Language-Action Models (VLAs) 는 로봇 액션을 직접 생성함으로써 VLMs의 능력을 확장하고, 인지와 운동 제어를 효과적으로 연결합니다. RT-1 및 RT-2와 같은 초기 연구는 액션을 discrete tokens으로 표현하는 패러다임을 확립하여, 사전 학습된 언어 모델이 텍스트 생성과 유사한 방식으로 로봇 명령을 출력할 수 있게 했습니다. 이러한 토대 위에 OpenVLA와 OpenVLA-OFT는 모델 크기를 더욱 줄이고 추론 효율성을 개선했습니다. 최근의 노력은 VLAs를 두 가지 상호 보완적인 방향으로 밀어붙이고 있습니다.
첫째, vision encoding의 개선은 순수 2D 지각의 한계를 극복하는 것을 목표로 합니다. SpatialVLA, GeoVLA, EVO-0, PointVLA는 입력 이미지 속 객체들에 대한 depth 정보를 통합하여 공간 지각 능력을 강화하고 태스크 성공률을 높였습니다. 둘째, action decoding의 발전은 이산 액션 토큰과 연속 제어 사이의 간극을 메우는 데 집중합니다. Nora, $\pi_{0.5}$ $\pi_0$-FAST와 같은 모델들은 이산 토큰 출력을 연속적인 액션 값으로 변환하여 더 정밀하고 빠른 실행을 가능하게 합니다. 아키텍처적 개선을 넘어, UniVLA 및 WorldVLA와 같은 새로운 패러다임은 world-modeling을 VLA 프레임워크에 통합합니다. 미래의 관측치를 공동으로 예측하고 액션을 생성함으로써, world models는 환경의 기저에 깔린 물리학을 포착하며 이는 더 정확한 액션 토큰 생성에 도움을 줍니다.
그러나 기존의 VLAs는 여전히 모델이 task-irrelevant tokens에 과도하게 집중하는 문제에 직면해 있으며 이는 액션의 질을 저하시키고 태스크 성공률을 낮출 수 있습니다. 몇몇 연구들은 시각적 노이즈를 완화하거나 태스크 관련 영역을 강조하려 시도했습니다. 예를 들어, BYOVLA는 시각적 민감도에 따라 입력 이미지를 수정하는 런타임 관측 개입 스킴을 제안하며, Otter는 추가적인 모델 구성 요소와 end-to-end 학습을 통해 text-aware feature filtering 을 학습하는 아키텍처를 도입합니다. 이러한 접근 방식은 견고성을 향상시키지만, 입력 레벨에서 작동하거나 아키텍처 재설계 및 학습을 요구하므로 기존 VLA 시스템에 광범위하게 적용하기 어렵습니다. 이러한 한계가 본 연구의 동기가 되었습니다: 즉, 기존 VLA 시스템에 광범위하게 적용 가능한 inference-time, training-free, 그리고 architecture-agnostic 방법을 개발하여 이러한 distracting tokens를 감지하고 제거함으로써, 모델의 시각적 attention을 정제하고 액션 생성의 정밀도를 향상시키는 것입니다.
3. METHOD

본 연구의 방법은 distracting tokens을 찾아내고 제거하기 위한 3 가지 단계로 구성됩니다. 첫째, 사용자의 의도된 task와 가장 관련이 깊은 visual tokens를 식별하기 위해 prompt-to-visual relevance를 분석합니다. 다음으로, 생성 관점에서 weighted self-attention 분석을 수행합니다. 마지막으로, 두 가지 관점을 모두 조화시킨 dynamic intersection-based pruning 전략을 적용하여 이미지 토큰을 선택적으로 제거합니다. 이러한 다단계 설계는 모델이 각 생성 단계에서 자신의 visual attention patterns를 자동으로 교정할 수 있도록 돕습니다.
3.1. Problem Formulation
$M$개의 이미지 토큰 수를 나타내는 $V \in \mathbb{R}^{M \times d}$의 visual tokens를 처리하는 VLA 모델 $F$가 주어졌을 때, 우리의 목표는 distracting image tokens를 제거하여 $|V'| = K$ (여기서 $K < M$)를 만족하는 서브셋 $V' \subset V$를 식별하는 것이며, 이를 통해 개선된 태스크 성공률 $Succ_F(V') \ge Succ_F(V)$을 산출하는 것입니다.
3.1.1. Important Region Construction
먼저prompt tokens와의 상호작용을 기반으로 visual tokens에 대한 relevance score를 계산합니다. $P$를 prompt tokens의 세트, $V$를 visual tokens의 세트, 그리고 $C$를 선택된 레이어들의 세트라고 가정합시다. 각 레이어 $c \in C$와 각 prompt token $p_i \in P$에 대해, 모든 visual tokens에 대한 relevance scores를 다음과 같이 계산합니다:
여기서 $A_h^c \in \mathbb{R}^{S \times S}$는 레이어 $c$의 헤드 $h$에서의 attention matrix이며, $S$는 전체 토큰 수(텍스트, 시각, 시스템 등)입니다. $A_h^c [p_i, V]$는 해당 헤드에서 prompt token $p_i$가 모든 visual tokens $V$에 보내는 attention weights를 선택합니다. $H$개의 헤드에 대해 평균을 내면 레이어 $c$에서 prompt token $p_i$에 대한 각 visual token의 전반적인 중요도를 나타내는 relevance vector $r_{p_i}^c \in \mathbb{R}^M$이 생성됩니다.
입력 시퀀스에서 이미지 토큰이 prompt tokens 뒤에 배치되어 prompt tokens가 이미지 토큰에 대해 attention을 가지지 않는 모델(예: UniVLA)의 경우, 우리는 대신 embedding similarity를 사용하여 relevance heatmap을 계산합니다.
여기서 $E_{p_i} \in \mathbb{R}^d$와 $E_V \in \mathbb{R}^{M \times d}$는 각각 prompt token과 visual tokens의 임베딩입니다. 그 다음 prompt tokens와 레이어 전체를 한 단계로 집계하여, visual tokens에 대한 전반적인 relevance heatmap $R$을 얻을 수 있습니다:
corner artifacts를 줄이고 중앙 영역에 집중하기 위해, corner suppression과 Gaussian smoothing을 사용한 spatial biasing을 적용합니다. 마지막으로, 가장 높은 관련성을 가진 $k$개의 visual tokens를 식별하여 important region $G$를 형성합니다.
3.2. VISUAL ATTENTION PATTERN CONSTRUCTION
액션 생성 중에서는 모델이 어떤 visual token에 집중을 기울이는지 분석하기 위해, 생성된 각 action token에 대해 visual attention pattern을 계산합니다. 각 action token $t_j$와 모델의 전체 레이어 수인 각 레이어 $l \in {1, \dots, N}$에 대하여, 먼저 $t_j$에서 모든 visual tokens로의 attention weights를 추출하여 레이어별 히트맵 $A_j^l \in \mathbb{R}^M$을 생성합니다. 그런 다음 각 레이어의 히트맵에 해당 레이어의 visual attention 비율인 $w^l$로 가중치를 부여하고, 레이어 전체에 걸쳐 합산하여 최종 visual attention pattern을 얻습니다:
여기서 $A_j \in \mathbb{R}^M$는 action token $t_j$를 생성하는 동안 모델이 각 visual token에 할당하는 전반적인 attention을 나타냅니다. 이 최종 히트맵은 action token 생성 중에 모델이 어떤 이미지 토큰에 가장 많은 주의를 기울이는지를 나타냅니다.
3.3. DISTRACTING TOKEN PRUNING

relevance heatmap에서 얻은 중요 영역 $G$와 visual attention pattern $A$가 주어지면, $G$의 내부와 외부의 attention 값을 비교하여 distracting visual tokens를 식별합니다.
중요 attention 영역 $A_g$ 내에 위치한 visual tokens 중 최대 attention 값을 $a_m$이라고 합시다. 중요하지 않은 attention 영역 $A_u$에 위치한 각 visual token $v$에 대하여, 만약 해당 토큰의 attention이 임계값이 적용된 최댓값을 초과하면 이를 distracting token $d$로 정의합니다:
여기서 $\tau$는 tolerance factor(허용 오차 범위)이며 $D$는 모든 distracting tokens의 세트입니다. 마지막으로, $D$에 속한 모든 distracting tokens는 정제된 action token을 생성하기 위해 입력에서 pruned됩니다. 서로 다른 모델과 태스크에 대한 이 과정의 시각화는 그림 3을 참조하십시오.
4. EXPERIMENTS
4.1 MAIN RESULTS



DTP는 SpatialVLA, Nora, UniVLA 등 다양한 Transformer 기반 VLA 모델의 성능을 일관되게 향상시켰습니다. SIMPLER Benchmark의 WidowX 태스크(표 1 참조)에서 SpatialVLA는 성공률이 29.2%에서 37.5%로(+28.4% 상대 향상), Nora는 6.2%에서 11.5%로 약 2배 가까이 수직 상승했습니다. 가장 강력한 베이스라인인 UniVLA 역시 74%로 성능이 개선되었습니다. Google Robot 태스크(표 2)와 LIBERO Benchmark(표 3)에서도 성능 향상이 확인되었으며, 이는 DTP가 특정 로봇이나 아키텍처에 국한되지 않고 노이즈를 효과적으로 억제하여 범용적인 성능 개선을 이끌어냄을 입증합니다.
4.2. Performance Upper Bound
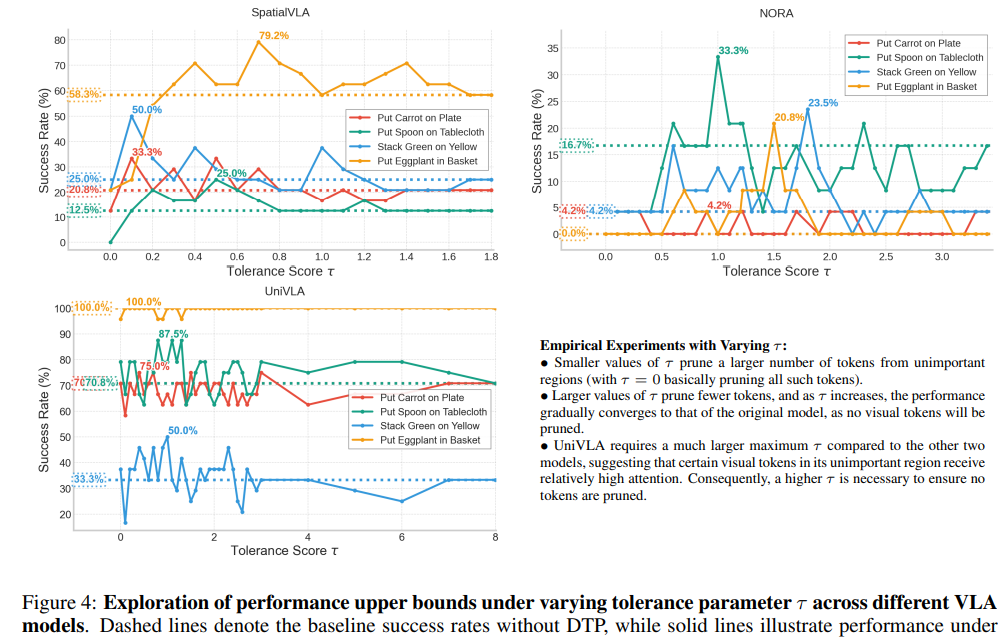
본 연구는 기존 아키텍처 내에서 서로 다른 시각적 주의력 패턴($\alpha$)이 정답 액션 토큰($A^*$)에 대한 모델의 불확실성에 어떤 영향을 미치는지 분석하여, VLA 모델이 달성 가능한 성능의 상한선을 조사합니다.
Conditional Uncertainty
시각적 주의력 패턴 $\alpha$ 하에서 모델의 불확실성 $E(\alpha)$는 다음과 같이 정의됩니다:
- 의미: $\alpha$에 의해 선택된 시각적 특징($Z_\alpha$)을 관찰한 후에도 정답 액션 토큰($A^*$)에 대해 모델이 느끼는 남은 불확실성(엔트로피)을 측정합니다.
- 해석: $E(\alpha)$ 값이 크면 주의력 패턴에 Distracting Tokens(방해 토큰)나 무관한 정보가 많이 포함되어 있음을 의미하며, 값이 작으면 태스크와 관련된 핵심 영역에 집중하고 있음을 나타냅니다.
Normalized Performance Score
태스크 자체의 고유한 모호성 대비 주의력 패턴이 얼마나 유용한 정보를 제공하는지 측정하기 위해, 정답 액션 분포의 엔트로피로 정규화합니다:
- $H(A^*)$: 시각적 입력을 고려하기 전, 정답 액션에 대한 베이스라인 불확실성입니다.
- $P(\alpha) \in [0, 1]$: 성능 지표로서, $1$이면 완벽한 확신을 의미하고 $0$이면 시각적 주의력이 아무런 유용한 정보를 제공하지 못함을 의미합니다.
Optimal Attention Pattern
가장 높은 성능을 내는 최적의 설정 $\alpha^*$는 조건부 불확실성을 최소화하는 패턴으로 정의됩니다:
Approximating the optimal pattern via DTP.
실제로 $\alpha^$를 직접 찾아내기는 어렵습니다. DTP는 허용 오차 인자 $\tau$를 사용하여 방해 토큰을 제거함으로써 유도된 패턴 $\alpha_\tau$를 생성하고, 이를 통해 $\alpha^$에 근사합니다. 최적의 $\hat{\tau}$를 찾음으로써 다음과 같은 성능 관계를 가집니다:
- $\alpha_{def}$: 모델의 기본(수정 전) attention pattern.
- $\hat{\alpha}$: DTP를 통해 찾은 최선의 하위 최적(sub-optimal) 패턴.
4.3. Ablation Studies
DTP 프레임워크 내의 각 구성 요소에 대한 유효성을 검증했습니다(표 4, 5 참조). 전체 영역이나 무관 영역에서 무작위로 토큰을 제거하는 전략은 오히려 성공률을 떨어뜨린 반면, 중요 영역 구축 시 Gaussian smoothing과 Corner suppression을 사용하지 않은 버전보다 제안된 전체 DTP 방식이 가장 우수했습니다. 이는 단순히 토큰을 줄이는 것이 아니라, 정교하게 task irrelevant token 을 식별하고 제거하는 것이 견고한 성능 향상의 핵심임을 방증합니다.
4.4. ANALYSIS OF ATTENTION IN UNIMPORTANT REGION AND TASK SUCCESS

task\ 성능에서 중요하지 않은 영역(unimportant region, $A_u$)에 대한 attention이 어떤 역할을 하는지 분석했습니다.
- 분석 방법:
- 무관한 시각 정보에 할당된 attention 총합을 측정하고, 에피소드를 성공과 실패 카테고리로 그룹화했습니다.
- Mann-Whitney U test를 통해 성공/실패 그룹 간의 unimportant attention 값에 유의미한 차이가 있는지 검사했습니다.
- 주요 발견:
- 높은 상관관계: 모든 모델에서 실패한 에피소드는 성공한 에피소드보다 무관 영역에 대한 attention이 일관되게 높았습니다($p < 0.001$). 이는 attention leakage(주의력 누출)가 태스크 실패와 강력하게 연결되어 있음을 시사합니다.
- 결정적 시점 (Middle Phase): 시계열 분석 결과(그림 5 참조), 로봇이 목표 물체를 grasping하고 조작하기 시작하는 궤적의 중간 단계에서 성공과 실패 그룹 간의 주의력 격차가 가장 뚜렷하게 나타났습니다.
- VLA의 고유한 약점: 이러한 현상은 특정 모델에 국한되지 않고 다양한 아키텍처와 로봇 플랫폼에서 공통적으로 관찰되었습니다. 즉, 현재 VLA 파이프라인이 중요한 조작 단계에서 주의력을 잘못 할당하는 체계적인 취약점을 가지고 있음을 실증적으로 입증한 것입니다.
5. CONCLUSION
본 연구에서 우리는 Vision-Language-Action (VLA) 모델을 평가하기 위한 간단하면서도 효과적인 plug-and-play 프레임워크인 Distracting Token Pruning (DTP)를 도입했습니다. DTP는 태스크와 무관한 영역의 distracting tokens를 동적으로 감지하고 제거함으로써, 보다 정확한 액션 토큰 생성을 위해 시각적 attention patterns를 교정합니다. 우리의 방법은 강력한 정책과 약한 정책 모두에 이득을 주며, 다양한 로봇에 걸쳐 일반화됩니다. SIMPLER Benchmark와 LIBERO Benchmark에서의 실험은 태스크 성공률의 일관된 향상을 입증했습니다.
또한, 적절한 허용 오차 $\tau$ 설정을 통해 원래의 아키텍처 하에서 모델의 성능 상한선을 탐색할 수 있습니다. 절제 연구는 무작위 또는 단순화된 베이스라인보다 우리의 타겟팅된 pruning 전략이 필요함을 더욱 확증했습니다. 마지막으로, 우리의 분석은 중요하지 않은 attention과 태스크 성공 사이의 음의 상관관계를 밝혀냈으며, attention leakage(주의력 누출)가 로봇 조작 실패의 공통적인 원인임을 강조했습니다. 이러한 발견은 더 견고한 embodied AI 시스템을 구축하는 데 새로운 통찰력을 제공합니다.
