논문 주소: https://arxiv.org/pdf/2503.07511
Abstract

광범위한 2D visual-language pretraining을 활용하여 VLA 모델들은 로봇 작업에서 우수한 성능을 보여주지만, RGB 이미지에 대한 의존은 실제 환경 상호작용에서 중요한 spatial reasoning을 제한합니다. 이러한 모델들은 3D 데이터를 사용해 재학습하는 것은 계산 비용이 매우 높으며, 기존 2D dataset을 버리는 것은 중요한 자원의 낭비입니다. 이러한 간극을 해소하기 위해, 본 논문에서는 PointVLA를 제안합니다. PointVLA는 재학습 없이 point cloud 입력을 사용해 pre-trained VLA를 향상시키는 framework입니다. 제안된 방식은 vanilla action expert를 freeze한 상태에서 lightweight modular block을 통해 3D feature를 주입합니다. 가장 효과적인 point cloud representation 결합 방식을 찾기 위해 skip-block analysis를 수행하여 vanilla action expert 내부에서 덜 중요한 block을 식별하고, 이러한 block에만 3D feature를 주입함으로써 pre-trained representation에 대한 교란을 최소화합니다.
광범위한 실험을 통해 PointLVLA는 시뮬레이션 및 실제 로봇 작업 전반에서 OpenVLA, Diffusion Policy, DexVLA와 같은 최첨단 2D imitation learning 방법들을 능가함을 확인했습니다. 특히 point cloud integration이 가능하게 만든 PointVLA의 여러 핵심 장점을 강조합니다: (1) Few-shot multi-tasking — PointVLA는 각 task당 단 20개의 demonstration만으로 네 가지 서로 다른 task를 성공적으로 수행합니다. (2) Real-vs-photo discrimination — PointVLA는 3D world knowledge를 활용하여 실제 물체와 사진 이미지를 구분해 안전성과 신뢰성을 향상시킵니다. (3) Height adaptability — 기존 2D imitation learning 방법과 다르게, PointVLA는 train 데이터에 존재하지 않았던 다양한 table height의 object에 적응할 수 있게 합니다. 또한 PointVLA는 이동하는 conveyor belt에서 물체를 pick & pack하는 long-horizon task에서도 강력한 성능을 보여주며, 복잡하고 dynamic한 환경 전반에서 generalization 능력을 입증합니다.
1. Introduction
Robot foundation models, 특히 Vision-Language-Action(VLA) 모델은 로봇이 물리 세계를 인지하고 이해하며 상호작용하는 능력에서 놀라운 성과를 보여주었습니다. 이러한 모델들은 pre-trained vision-language model을 backbone으로 활용하여 시각 정보와 언어 정보를 처리하고, 이를 공유된 represenatation space로 embedding한 뒤, robot action으로 변환합니다. 이 과정은 로봇이 환경과 의미 있는 방식으로 상호작용할 수 있도록 합니다.
VLA 모델들의 성능은 training data의 규모와 품질에 크게 의존합니다. 예를 들어, OpenVLA 는 4k 분량의 open-source dataset으로 학습되었고, 더욱 발전된 모델인 π0는 10k 시간의 proprietary data를 사용하여 훨씬 향상된 성능을 얻었습니다. 또한 다양한 프로젝트에서 실제 로봇의 human demonstration 기반 dataset이 대규모로 구축되었습니다. 예를 들어, AgiBot-World 는 humanoid interaction이 포함된 수백만 개의 trajectory를 공개했습니다. 이러한 pre-trained VLA 모델과 공개 로봇 dataset은 로봇 학습의 발전을 크게 이끌었습니다.
하지만 이러한 발전에도 불구하고 기존 robot foundataiton models의 대부분은 2D visual input 만으로 학습되었습니다. 이는 중요한 한계를 의미합니다. 인간은 세계를 3D로 인지하고 상호작용하며, 로봇 역시 3D spatial 정보를 필요로 합니다. 3D 공간을 충분히 이해하지 못하면 깊이 판단, 정확한 object manipulation, 정밀한 공간 인식이 필요한 작업에서 성능을 충분히 발휘하기 어렵습니다. 특히 이미 많은 기관이 기존 VLA 모델과 대규모 2D robot dataset에 막대한 자원을 투자해왔다는 점이 중요한 동기입니다. 이러한 모델을 3D 데이터로 처음부터 재학습하는 것은 계산 비용이 매우 크며, 기존 2D 데이터를 버리는 것도 비현실적입니다. 따라서 기존 foundation robot model을 유지하면서 새로운 3D input을 통합할 수 있는 framework가 필요하며, 이는 기존 연구에서 충분히 탐구되지 않았던 영역입니다.
본 논문에서는 pre-trained VLA에 point cloud를 통합하는 새로운 framework인 PointVLA를 소개합니다. 본 연구에서는 새로운 3D robot data의 규모가 기존 pre-trained 2D data보다 훨씬 작다고 가정합니다. 이런 상황에서는 이미 잘 형성된 2D feature representation을 훼손하지 않는 것이 중요합니다. 이를 위해 action expert 내부에 point cloud 정보를 직접 주입하는 3D modular block을 제안합니다. vision-language backbone은 freeze하여 2D visual-text embedding을 그대로 유지합니다.
또한 action expert의 feature space를 불필요하게 교란하지 않기 위해 skip block analysis를 수행하여 test-time 기준으로 중요하지 않은 block을 식별합니다. 이러한 “덜 중요한” block은 새로운 modality에 더 쉽게 적응할 수 있으며, 이 block들에만 3D feature를 additive 방식으로 주입합니다. 이러한 설계는 pre-trained VLA의 안정성을 유지하면서도 point cloud 입력의 장점을 효과적으로 통합합니다.
본 연구에서 제안한 방법의 효과를 실증적으로 검증하기 위해 광범위한 실험을 수행했습니다. 예를 들어 RoboTwin 시뮬레이션 플랫폼에서 본 방법은 순수 3D imitation learning 방식인 3D Diffusion Policy 보다 우수한 성능을 보였습니다. 또한 실제 실험에서는 humanoid-like UR5e 팔과 AglieX 팔(Aloha 플랫폼 유사)을 사용하여 다양한 bimanual robot 환경에서 실험을 수행했습니다.
추가적으로 PointVLA의 다음과 같은 주요 장점을 확인했습니다:
- Real-vs-photo discrimination: 2D 이미지에서는 real object와 그 사진이 매우 유사하게 보일 수 있어 로봇이 실수하거나 안전 문제가 발생할 수 있습니다. PointVLA는 3D world knowledge를 활용하여 실제 물체와 사진 이미지를 명확히 구분할 수 있습니다.
- Height adaptability: PointVLA는 table height가 바뀌는 상황(예: 더 높은 테이블에 놓인 물체를 잡는 경우)에서도 안정적으로 행동할 수 있습니다. 기존 2D VLA 모델은 이런 unseen height shift 상황에서 대부분 실패합니다.
또한 conveyor belt에서 여러 물체를 순차적으로 pick하여 box에 pack하는 long-horizon 작업에서도 PointVLA는 강력한 성능을 보여주었습니다. 이는 PointVLA가 다양한 복잡하고 dynamic한 환경에서도 generalization 능력을 가진 framework임을 보여줍니다.
2. Related Works
Vision-Language-Action models.
최근 연구에서는 대규모 robotic learning dataset을 활용하여 generalist robot policy를 개발하는 데 점점 더 집중하고 있습니다. Vision-Language-Action(VLA) 모델은 이러한 정책을 학습하기 위한 유망한 접근법으로 부상했습니다. VLA는 인터넷 규모의 image–text dataset 에서 pre-training된 Vision-Language model(VLM)을 로봇 제어로 확장한 구조입니다.
이 접근 방식은 여러 가지 중요한 장점을 제공합니다. 수십억 개의 parameter를 가진 대규모 vision-langauge backbone을 활용함으로 써 방대한 robotic dataset으로부터 효과적으로 학습할 수 있으며, 인터넷 규모의 pre-trained weight를 재사용함으로써 다양한 language command를 해석하고 새로운 object와 환경에 generalize하는 능력이 향상됩니다. 이러한 특성은 실제 환경에서 로봇이 높은 적응성을 갖도록 하는 데 매우 유리합니다.
Robot learning with 3D modalities.
3D scene에서 강건한 visuomotor policy를 학습하는 것은 로봇 학습의 중요한 영역입니다. 기존 연구 중 3DVLA와 같은 접근법은 generalization, visual question answering(VQA), 3D scene understanding, robot control 등 다양한 3D task를 하나의 unified vision-language-action model로 통합하는 포괄적인 framework를 제안했습니다. 그러나 3DVLA는 robot control 실험에서 simulation에 의존한다는 한계가 있으며, 이는 sim-to-real gap을 크게 야기합니다.
또 다른 연구인 3D diffusion policy는 외부 카메라 등 extrinsic 3D input을 활용하면 다양한 조명 조건 및 object 속성 변화에 대한 일반화 능력이 향상됨을 보였습니다. iDP3는 3D visual encoder를 강화하고 이를 humanoid robot에 적용하여 egocentric 및 external view 모두에서 안정적인 성능을 달성했습니다.
하지만 기존의 2D robot data를 폐기하거나 새롭게 추가된 3D visual input으로 foundation model을 처음부터 재학습하는 것은 계산 비용과 자원 소모가 매우 크다는 문제가 있습니다. 따라서 더 실용적인 해결책은, 잘 pre-training된 foundation model의 성능을 해치지 않으면서 3D visual input을 보조적인 knowledge source로 통합하는 방법을 개발하는 것입니다. 이러한 접근은 새로운 modality의 장점을 활용하면서도 기존 모델의 안정성을 유지할 수 있다는 점에서 더욱 현실적입니다.
3. Methodology
3.1. Preliminaries: Vision-Language-Action Models
Vision-Language-Action 모델은 실제 환경에서 robot learning에 큰 변화를 이끌고 있습니다. 이러한 모델의 강점은 방대한 인터넷 데이터로 pre-training된 vision Langauge Model을 기반하며, 이는 image와 text representation을 shared embedding space에서 효과적으로 alignment하도록 합니다. VLM은 모델의 'brain'으로 작동하며, instruction과 현재 visual input을 처리해 task state를 이해합니다. 이후 'action expert' 모듈이 VLM의 state 정보를 robot action으로 변환합니다.
본 연구는 DexVLA 를 기반으로 합니다. DexVLA는 2 billion parameter 규모의 Qwen2-VL VLM 을 backbone으로 사용하고, 1 billion parameter 규모의 ScaleDP(diffusion policy의 변형)을 action expert로 사용합니다. DexVLA는 세 단계의 training 절차를 거칩니다: 100시간 cross-embodiment training(Stage 1), embodiment-specific training(Stage 2), 그리고 복잡한 task를 위한 optional task-specific training(Stage 3)입니다. 세 단계 모두 2D visual input만을 사용합니다.
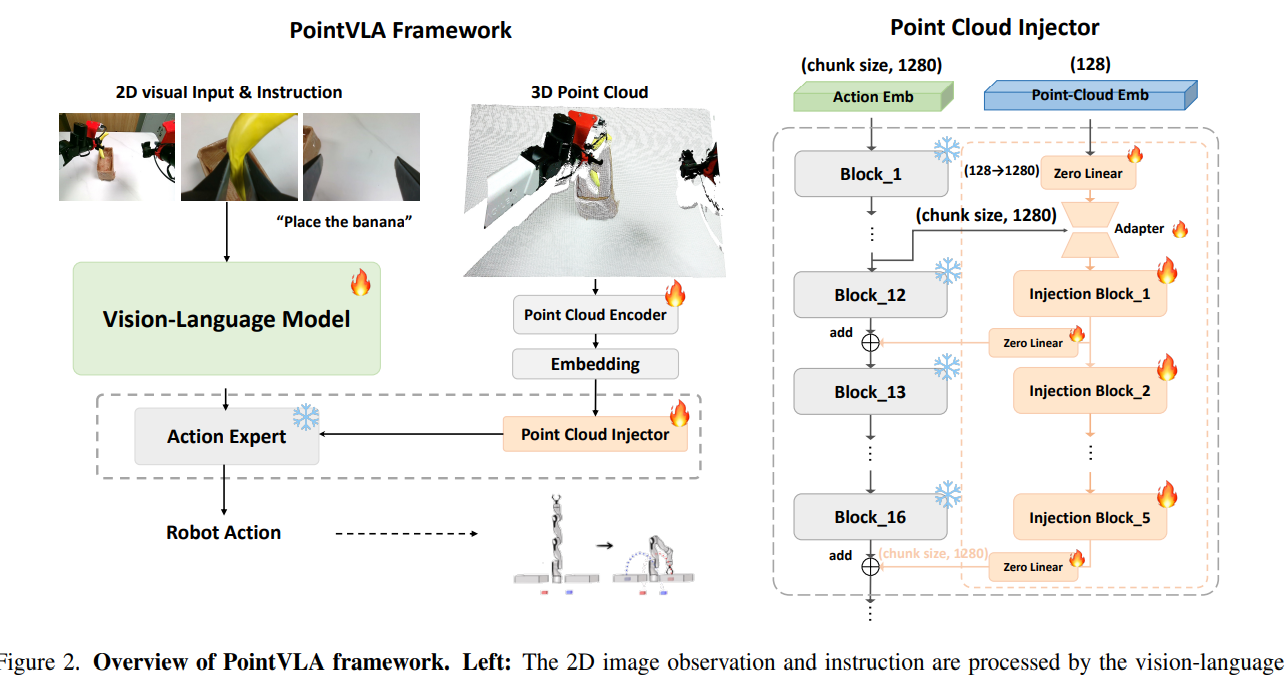
이들 VLA 모델은 다양한 manipulation task에서 인상적인 성능을 보이지만, 2D vision에 대한 의존성 때문에 3D 이해가 필요한 task, 예를 들어 사진으로 인한 object deception 또는 다양한 table height generalization과 같은 문제에서는 한계가 존재합니다. 다음 섹션에서는 pre-trained VLA에 3D world를 어떻게 주입하는지 설명합니다. 전체 framework는 Figure 2에 나타나 있습니다.
3.2. Injecting Point Cloud into VLA
Motivation.
이전 논의에서 살표 보았듯이, VLA 모델은 대규모 2D robotic dataset으로 pre-trianing되는 경우가 대부분입니다. 여기에서 핵심 관찰은 기존 2D pretraining corpus와 새롭게 등장하는 3D robotic dataset의 규모 차이가 매우 크다는 겁니다. 특히 3D sensor data (예: point cloud, depth map)는 2D vision-language dataset에 비해 훨씬 적으며, 이는 오랜 기간 robotics 연구가 2D perception 중심으로 발전해 온 역사적 흐름 때문입니다. 이러한 차이는 2D pretraining에서 획득한 rich visual representation을 보존하면서 sparse한 3D 데이터를 효과적으로 통합하는 방법론이 필요함을 의미합니다.
가장 단순한 접근은 3D visual input을 3D visual token으로 변환한 뒤 LLM에 직접 주입하는 것입니다. 이는 LLaVA-3D 등 여러 3DVLM에서 널리 사용되는 전략입니다. 하지만 이러한 방식은 작은 규모의 3D dataset으로 fine-tuning할 때 다음과 같은 한계에 부딪힙니다:
- 2D pixel과 3D geometric structure 사이의 domain gap이 크다는 점
- 고품질 3D-text paired data의 부족
이 문제를 피하기 위해, 본 연구는 3D point cloud data를 primary input modality로 쓰는 대신 complementary conditioning signal로 취급하는 접근을 제안합니다. 이 전략은 3D processing을 core 2D visual encoder와 분리하여, pretrained 2D represenatation의 integrity를 보존하면서도 3D geometric cue를 활용할 수 있도록 합니다. 결과적으로 이 방식은 2D knowledge의 catastrophic forgetting을 방지하고, 한정된 3D 데이터에 대한 overfitting 위험을 줄입니다.
Model architecture for point cloud injector.
전체적인 point cloud injector 구조는 Figure 1(right)에 제시되어 있습니다. 입력된 point cloud embedding은 먼저 vanilla expert의 channel dimenstion과 일치하도록 변환합니다. point cloud 기반 action embedding은 chunk size에 따라 커질 수 있으므로, 본 연구에서는 action expert의 정보를 압축하고 3D point cloud embedding과 정렬시키기 위해 action embedding bottleneck 구조를 설계했습니다. 선택된 action expert block마다 MLP adapter layer를 적용한 후, addition 연산을 통해 point cloud embedding을 모델 내부로 주입합니다.
모든 block에 3D feature를 넣지 않은 이유는 다음과 같습니다:
- conditioning block을 모든 layer에 추가하면 computational cost가 지나치게 커짐
- 모든 block이 변형되면 pretrained 2D visual 기반의 action embedding이 크게 훼손됨.
따라서 inference 시 성능에 영향을 주지 않고 skip 가능한 block을 분석하여, 그 block들에만 selective injection을 수행했습니다.
Point cloud encoder.
DP3와 iDP3의 관찰과 일치하게, pretrained 3D visual encoder는 성능을 저해하며 새로운 환경에서 robot behavior learning을 방해하는 경우가 많았습니다. 이에 따라 본 연구에서는 단순하고 계층적 구조의 convolutional architecture를 채택했습니다.
- 상위 convolution layer: low-level feature 추출
- 하위 convolution block: high-level scene representation 학습
- max pooling: point cloud density를 점진적으로 감소
- 최종적으로 각 계층의 feature embedding을 concat하여 multi-level 3D representation을 구성
이 encoder는 iDP3와 유사합니다. 더 발전된 point cloud encoder를 적용하면 성능이 증가할 수 있으나, 이는 본 연구의 핵심 기여가 아니므로 향후 연구에서 다루기로 합니다.
3.3. Which Blocks to Inject Point Cloud? A Skip Block Analysis


모든 block에 point cloud를 주입하면 계산 비용이 증가하고, 2D visual-based representation을 훼손하는 문제가 있습니다. 따라서 어떤 block이 중요도가 낮아 skip이 가능하며, 성능 영향을 주지 않는지를 분석했습니다. 이는 이는 image generation, vision model, LLM 연구에서 사용되는 skip-layer 분석 기법과 유사합니다.
DexVLA의 shirt folding task를 case study로 사용했습니다. DexVLA의 action expert는 32개의 diffusion trasnformer block으로 구성된 1 billion parameter 모델입니다. 평가 방식은 long-horizon task에서 표준적으로 사용하는 average score metric을 사용하여, task를 여러 단계로 나누고 각 step completion을 기준으로 성능을 측정합니다.
본 연구에서는 한 번에 하나의 block을 skip 하여 성능 변화를 측정했습니다.
Figure 3(left)의 결과는 다음을 보여줍니다:
- 첫 11개 block은 매우 중요
→ 이 block들을 skip하면 성능이 크게 떨어지고, gripper가 제대로 닫히지 않아 task를 수행하지 못함 - 11번째 block 이후로는 skip이 허용되며, 마지막 block까지 비교적 영향이 적음
또한 Figure 3(right)의 multi-block skip 분석에 따르면:
- block 11 이후 연속적으로 최대 5개 block까지 skip 가능
- 이는 action expert의 특정 구간이 3D representation을 주입하기에 적합함을 시사
결론적으로,
- 3D conditioning block 5개만 trainable하게 설정
- vanilla action expert 전체는 freeze
- embodiment에 맞게 조정된 final layer만 수정
이로 인해 inference 속도가 빠르고 계산 비용이 낮아 매우 효율적인 구조가 됩니다.
4. Experiment
본 절에서는 제안한 접근 방식의 효과를 검증하기 위한 일련의 실험을 제시합니다. 구체적으로, 4.1절에서는 실제 로봇과 workspace 설정에 대한 세부 설명을 제공합니다. 4.2절과 4.3절에서는 각각 few-shot multi-tasking 설정과 long-horizon 도전적 task를 평가합니다. 4.4절과 4.5절에서는 3D visual input에서만 관찰 가능한 두 가지 독특한 generalization 유형을 탐구합니다. 마지막으로, simulation benchmark와의 비교 실험을 수행합니다.
4.1. Implementation Details
두 종류의 양팔 로봇(UR5e, AgileX)에서 실험을 수행했으며, wrist camera와 top camera를 포함해 3개의 시점에서 데이터를 수집했습니다. Point cloud는 RealSense L515로 수집했습니다. DexVLA의 pre-trained weight를 기반으로 fine-tune하고, PointVLA는 DexVLA에 3D point cloud 통합만 추가한 구조로 baseline과 비교했습니다.
4.2. Few-Shot Multi-Tasking

Task description.
Fig 5에 나타난 바와 같이, 실제 환경에서 네 가지 few-shot task를 설계했습니다: ChargePhone, WipePlate, PlaceBread, TransportFruit 입니다. 객체는 작은 범위 내에서 무작위로 배치되며, 각 방법의 평균 성공률을 보고합니다.
- ChargePhone: 스마트폰을 집어 무선 충전기에 올려놓는 task입니다. 작은 크기 때문에 정밀한 action이 필요하며, 파손 방지를 위해 섬세한 조작이 요구
- WipePlate: 스펀지와 접시를 동시에 집어 접시를 닦는 bimanual manipulation task
- PlaceBread: 빵 조각을 집어 접시에 올려놓는 task입니다. 빵 아래에 얇은 foam layer가 있어 height generalization을 확인
- TransportFruit: 임의의 방향을 가진 바나나를 집어 중앙의 박스에 옮겨놓는 task
Few-shot multitasking 능력을 검증하기 위해 각 task당 20개의 demonstration을 수집하여 총 80개의 demonstration을 구성했습니다. 객체 위치는 작은 공간 내에서 무작위 배치됩니다. 이 task들은 로봇이 다양한 상황에서 독립적·협력적 조작을 수행할 수 있는지 평가합니다. 모든 데이터는 30Hz로 수집됩니다.
Experimental results.

Table 6의 실험 결과에서 보듯이, 본 방법은 모든 baseline보다 우수한 성능을 보입니다. 특히 Diffusion Policy는 대부분의 상황에서 실패하는데, 이는 각 task의 sample 수가 너무 적어 action representation space가 얽히는 문제 때문이며 기존 문헌에서도 동일한 관찰이 보고되었습니다. 모델의 규모를 증가시킨 ScaleDP-1B조차 크게 개선되지 않았습니다.
DexVLA 역시 제한된 데이터에서도 강력한 few-shot 학습 능력을 보이지만, 전반적으로 PointVLA와 비슷하거나 더 낮은 성능을 보입니다. PointVLA는 point cloud 데이터 통합을 통해 sample-efficient 학습을 달성하며, 3D 정보 통합의 필요성을 강조합니다. 특히 본 결과는 제안한 방법이 2D representation을 잘 보존하면서 성능 향상을 이끈다는 점을 확인시켜줍니다.
4.3. Long-Horizon Task: Packing on Assembly Line
전통적인 multi-tasking을 넘어, PointVLA를 assembly line packing과 같은 long-horizon task에 대해 추가적으로 fine-tune했습니다(Figure 4 참고). 이 task는 매우 어려운 task이며, 그 이유는 다음과 같습니다.
- assembly line이 움직이기 때문에 빠르고 정밀한 grasping이 필요함
- 사용된 embodiment는 pre-trained data에 존재하지 않아 완전히 새로운 setup에 대한 빠른 적응이 요구됨
- 장기 task로서 세탁세제를 두 번 연속 pick & place한 후 박스를 sealing해야 함
평가 metric은 Appendix에 설명되어 있습니다. Table 1에서 보이듯이, PointVLA는 long-horizon task의 평균 길이에서 DexVLA보다 0.64 높은 점수를 기록하며 최고 성능을 달성했습니다. 또한 여러 baseline보다 우수한 결과를 보였습니다.
4.4. Real-vs-Photo Discrimination
본 절에서는 real-vs-photo discrimination이라는 독특한 setup을 탐구합니다. 실제 객체를 사진으로 대체하는 방식으로 실험을 구성합니다. 2D 관점에서 “fake” 객체(사진)는 실제 객체와 거의 동일해 보이나, 물리적으로 존재하지 않습니다. 인간은 이를 쉽게 구분하고 손을 뻗지 않지만, 로봇 모델도 같은 판단을 내릴 수 있을까요?
이를 확인하기 위해 bimanual UR5e가 수행하는 packing task에서 세탁세제를 사진으로 대체한 실험을 수행했습니다(Figure 7 참고). exocentric view에서는 사진이 실제 객체와 약간 다르게 보이지만, 한 장의 top-down egocentric camera에서는 거의 동일하게 보입니다.
OpenVLA, DexVLA와 같은 기존 2D 기반 VLA 모델은 이를 구분하지 못하고 객체를 집으려 하며, DexVLA는 존재하지 않는 물체를 반복적으로 grasp하려고 시도하는 looping 현상이 발생합니다. 모델은 객체가 있다고 “믿지만” 실제로 grasp하지 못하므로 계속 과정을 반복하게 됩니다.
반면 PointVLA는 conveyor belt 위에 실제 객체가 존재하지 않음을 성공적으로 판단했습니다. 3D spatial understanding을 통해 객체가 있어야 할 위치가 비어 있음을 인지한 것입니다. 이는 3D-aware 모델이 object hallucination을 효과적으로 완화할 수 있음을 보여주는 중요한 결과입니다.
4.5. Height Adaptability
Height generalization은 모델이 서로 다른 table height에 적응하는 능력을 의미합니다. 대부분의 demonstration은 고정된 table height에서 수집되기 때문에, 배포 환경에서 높이가 크게 다를 경우 2D 기반 모델은 실패할 가능성이 큽니다.
이를 평가하기 위해 Figure 8과 같은 실험을 설계했습니다. “place bread” task에서 빵 아래에 foam layer를 두었으며, training에서는 foam 두께가 3mm였습니다. inference 시에는 foam을 52mm로 증가시켜 height generalization을 평가했습니다.
OpenVLA, DP, ScaleDP-1B, DexVLA 등 2D 기반 VLA 모델은 모두 실패했습니다. 모델은 bread를 감지하지만, training에서 보았던 높이에 맞춰 동일하게 밑으로 밀어 넣으려 시도해 grasp에 실패합니다.반면 PointVLA는 point cloud 정보를 이용하여 새로운 높이를 정확히 인식하고 올바르게 gripper 높이를 조정해 성공적으로 pick 작업을 수행했습니다. 이는 3D 정보의 통합이 height variation을 처리하는 데 필수적임을 보여줍니다.
4.6. Experimental Results on Simulation Benchmarks
RoboTwin 시뮬레이션 플랫폼에서 평가를 수행했습니다. RoboTwin은 14-DoF mobile bimanual 로봇을 사용하며 다양한 task를 포함합니다. 비교 대상은 Diffusion Policy와 3D Diffusion Policy(DP3) [51]입니다. DP3는 point cloud만 입력으로 사용하는 purely 3D 모델입니다. 공정한 비교를 위해 RGB input을 추가한 DP3 버전도 포함했습니다.
20개, 50개 demonstration dataset에서 평가했으며, RoboTwin의 세팅을 따라 세 개의 random seed(0,1,2)로 학습 후 각 policy를 100번 평가하여 성공률의 평균과 분산을 계산했습니다.
Table 2에 제시된 결과에서, PointVLA는 모든 task 및 설정에서 최고 평균 성공률을 기록했습니다. 20개의 제한된 데이터에서도 강력하며, 50개의 더 많은 데이터에서도 안정적으로 우수한 성능을 보입니다. 또한 DP3와 같은 purely 3D 모델에 RGB를 직접 결합하면 성능이 저하되는 반면, 본 연구는 3D point cloud를 conditional하게 통합하는 접근이 2D-only 또는 3D-only 모델보다 훨씬 효과적임을 보여줍니다.
5. Conclusion
Vision-Language-Action 모델은 대규모 2D 사전 학습을 통해 로봇 학습에서 뛰어난 성능을 보이지만, RGB 입력에 의존하기 때문에 3D 공간 reasoning 능력에 한계가 있습니다. 3D 데이터를 활용해 모델은 다시 학습 하는 것은 비용이 매우 크며, 기존 2D dataset을 버리는 것은 일반화 능력을 저하시킵니다. 이를 해결하고자 본 연구에서는 사전 학습된 VLA에 3D point cloud 입력을 통합하면서도 기존 2D represenatation을 보존하는 PointVLA 프레임워크를 제안합니다.
PointVLA는 모듈형 3D feature injector와 skip block analysis를 활용하여 전체 모델 재학습 없이도 효율적으로 spatial 정보를 주입합니다. 시뮬레이션 및 실제 환경 모두에서 PointVLA의 성능이 입증되었으며, 특히 20개의 demostration만으로 4개의 task를 수행하는 few-shot multi-task 학습과, 동적 환경에서의 long-horizon 작업(예: conveyor belt 기반의 item packing)에서도 우수한 성능을 보여줍니다. 또한 UR5e 및 AgileX 양팔 로봇을 기반으로 한 실제 실험을 통해 실용성과 안전성이 확인되었습니다.
본 연구는 대규모 재학습 없이도 사전 학습된 로봇 모델에 새로운 modality를 확장할 수 있음을 보여주며, 향후에는 더 큰 규모의 dataset을 활용한 3D-aware pretraining으로 확장하는 방향이 남아 있습니다.
