논문 주소: https://arxiv.org/pdf/2510.10181
Abstract
Embodied agent는 근본적인 한계를 가지고 있는데, 실제 환경에서 배치되는 특정 작업을 수행하기 시작하면 추가적인 지식을 획득하여 작업 성능을 향상시키는 능력이 없다는 점입니다. 본 논문에서는 이러한 문제를 해결하기 위해 Experience Feedback Network(EFN)를 활용하고 frozen Vision-Language-Action(VLA) policy에 실행 중 수집된 memory retrieval 방식으로 결합하는 일반화된 post-deployment learning 프레임워크인 Dejavu를 제안합니다.
EFN은 현재 상황과 유사한 과거의 action 경험을 식별하고, 이 retrieval된 guidance를 기반으로 action prediction을 보조합니다. 본 연구에서는 semantic similarity reward를 사용하는 reinforcement learning을 통해 EFN을 학습하여, EPN이 현재 observation 하에서 과거 behavior와 일치하는 action을 예측하도록 합니다.
배치 중 EPN은 새로운 trajectory를 지속적으로 자신의 memory에 축적하며, 이를 통해 agent가 " 경험으로부터 학습하는(learning from experience)” 특성을 보이게 합니다. 다양한 embodied task에서의 실험 결과, EFN이 frozen baseline 대비 적응성, 강건성, 성공률을 모두 향상시킴을 확인했습니다. 코드와 데모는 supplementary material에서 제공합니다.
1. Introduction
Embodied intelligence는 환경과의 물리적인 상호작용을 통해 학습하고 행동하는 agent를 연구하는 분야입니다. 최근 통합 Vision–Language–Action(VLA) 모델은 다양한 작업 전반에서 뛰어난 generalization 능력을 보여주었지만, 이는 모두 고정된 데이터 분포에서의 대규모 offline training 이후에만 가능했던 성과입니다. 일단 deployment가 이루어지면, 이러한 모델의 weight(즉, 지식)은 더이상 업데이트 되지 않으며, retraining 없이는 확장이 불가능해집니다. 따라서 대부분의 실제 시스템은 배치 순간부터 사실상 “학습이 멈추는” 문제가 발생합니다.
이 지점에서 자연스럽게 다음 질문이 제기됩니다. "지능형 시스템은 성능 향상을 위해 반드시 내부 weight를 다시 써야만 하는가?" 인간은 새롱누 문제를 직면할 때, 전혀 새로운 사실을 배우지 않더라도 이전에 겪었던 경험을 떠올리고 재사용하는 방식으로 문제를 해결하는 경우가 많습니다. 이러한 episodic memoty는 “déjà vu” 감각을 만들어내며, core knowledge representation을 바꾸지 않으면서도 유사성을 기반으로 빠른 적응을 가능하게 합니다.
이와 같은 관찰을 바탕으로, 본 연구에서는 AI agent 또한 유사하게 자신의 과거 경험을 저장하고 회상함으로써 개선될 수 있는가라는 질문을 던집니다. 만약 neural network가 과거 상황과 해결책을 memory 형태로 저장하고 그것을 현재 판단에 활용할 수 있다면, gradient-based retraining 없이도 inference 과정에서 새로운 경험을 축적하고 활용하는 방식으로 시간이 지날수록 점점 더 나아질 수 있을 것입니다. 이러한 “learning from déjà vu”라는 개념이 본 연구의 핵심 동기입니다.
이와 밀접한 관련 분야로 retrieval-augmented reinforcement learning 및 retrieval-augmented embodied agent 연구가 있습니다. Retrieval-augmented RL은 외부 experience buffer를 policy 또는 value function과 결합하며, 현재 state와 유사한 trajectory를 검색하여 credit assignment 또는 value estimation을 향상시키는 방식입니다. Embodied 제어나 로봇 제어에서도, 최근 접근법들은 과거의 실행 trajectory 또는 policy snippet을 retrieval하여 의사결정에 활용합니다. 일부 방법은 검색된 데이터를 기반으로 fine-tuning을 수행하고, 다른 방법은 검색된 trajectory를 정책의 추가 context로 직접 제공하는 방식을 따릅니다.
하지만 기존 retrieval 방식들은 다음 한계를 갖습니다.
- 일반적으로 trainable policy를 개선하는 데 초점이 있어, 배치 중 또는 이후에도 weight 업데이트가 필요합니다.
- deployment 중 실시간으로 확장되는 live memory가 아닌, 고정된 offline buffer를 사용합니다.
- Retrieval은 compact한 state 또는 task abstraction을 사용하며, modern VLA가 제공하는 open-vocabulary vision–language interface 수준의 풍부한 표현을 활용하지 못합니다.
결과적으로 기존 방법들은 weight를 frozen한 통합 정책을 배치 시점에서 지속적으로 개선시키는 간단한 메커니즘을 제공하지 못합니다.
이를 해결하기 위해, 본 연구에서는 Experience Feedback Network(EFN)을 제안합니다. EFN은 pre-trained VLA policy의 weight를 변경하지 않고도 deployment 동안 성능을 향상시키는 experience-centric controller입니다. EFN은 현재 observation과 retrieval된 과거 experience에서의 action을 입력으로 받아 residual action을 예측하고, 이를 base VLA policy의 출력에 더함으로써 최종 제어 action을 생성합니다. 강력한 prior experience가 존재하는 경우, EFN은 이를 적극 활용하여 action을 정교하게 보정하고, retrieval 품질이 낮을 경우 base policy에 가깝게 되돌아갑니다.
EFN은 similarity-based dense reward를 사용하는 reinforcement learning으로 학습됩니다. Retrieval된 experience의 다음 observation과 현재 agent가 만든 다음 observation이 유사할수록 높은 보상을 부여하여, sparse한 성공/실패 신호를 넘어 지속적이고 풍부한 shaping signal을 제공합니다. 최적화는 soft actor-critic 알고리즘을 기반으로 수행됨며, entropy regualarization과 off-policy 효율을 활용해 저장된 경험을 효과적으로 재사용합니다.
Deployment 중 agent는 지속적으로 확장되는 live experience bank를 유지하며, 성공적인 rollout이 발생할 때마다 새로운 trajectory를 memory에 추가합니다. 매 inference 단계에서 agent는 vision–language embedding space에서 현재 observation과 유사한 trajectory를 retrieval하고, 해당 trajectory의 action을 EFN에 함께 전달하여 residual 보정을 수행합니다. 이를 통해 retrieval-augmented이지만 weight는 frozen VLA agent가 실시간 경험 축적만으로 성능을 스스로 향상시키는 구조를 달성합니다.
본 연구는 EFN을 OpenVLA, UniVLA, GO-1에 통합한 후, simulation과 실제 환경 모두에서 평가했습니다. 광범위한 실험에서 EFN은 강력한 VLA baseline은 물론 retrieval-only, residual-only, retrieval-augmented RL, test-time training 방법 모두를 능가하는 성능을 보였습니다
본 연구의 주요 기여는 다음과 같습니다.
- Frozen VLA policy에 episodic experience bank를 결합하여, backbone fine-tuning 없이 memory update만으로 배치 후 지속적 향상이 가능한 retrieval-conditioned residual 모듈 EFN을 제안했습니다.
- 시각–언어–행동 trajectory를 동기화된 형태로 저장하는 experience bank를 설계하고, joint embedding space에서 task-relevant transition을 retrieval하며, similarity-shaped reinforcement signal을 활용해 residual을 학습했습니다.
- EFN을 OpenVLA, UniVLA, GO-1에 통합하고 LIBERO 및 실제 AgiBot-G1 환경에서 평가하여, 동일한 경험량과 평가 방식 하에서 retrieval-only, residual-only, retrieval-augmented RL, test-time training baseline 대비 일관된 성능 향상을 입증했습니다.
2. Background
2.1. Vision-Language-Action (VLA) Models
대규모 VLA policy는 open-vocabulary perception과 end-to-end control을 결합하며, manipulation 작업에서 강력한 cross-task generalization을 달성합니다. 최근의 open-source generalist policy는 다양한 robot embodiment와 sensor로 확장되었으며, 경량화된 architecture는 배치 단계에서의 inference 효율성을 향상시키고 있습니다. 또한 LIBERO와 같은 benchmark는 compositional generalization 및 post-deployment robustness 평가를 표준화하고 있습니다. 본 연구에서는 이러한 VLA를 frozen backbone으로 바라보는 최근 관점을 채택합니다. 즉, VLA는 강력하지만 불완전한 policy를 제공하며, EFN은 backbone weight를 수정하지 않고 외부 correction module로만 동작하는 구조입니다.
2.2. Post-deployment Learning and Retrieval
배치 후 정책을 개선하는 것은 중요한 도전 과제이며, 특히 대규모 모델을 반복적으로 fine-tuning하지 않고 성능을 향상시키는 방법이 필요합니다. Human-in-the-loop 및 continual-learning 프레임워크는 로봇이 배치 중 피드백을 수집하고 온라인으로 적응하는 방법을 연구해왔습니다. 이와 병행하여, retrieval-augmented reinforcement learning은 외부 experience buffer를 policy 또는 value function과 연결하고, 테스트 시점에서 유사한 trajectory를 retrieval하여 의사결정을 보조합니다. 로봇 분야에서는 retrieval된 과거 episode, demonstration 또는 cached behavior를 기반으로 training- free guidance를 제공하는 방식이 사용되어 왔습니다.
한편 residual policy learning은 전체 action을 예측하는 대신 additive correction만을 예측함으로 써 강력한 controller를 더 안전하고 sample-efficient하게 개선할 수 있습니다. 유사도 기반의 dense reward 및 world model은 sparse reward 신호에만 의존하는 대신, 예측된 미래나 관찰된 미래를 목표 상태와 비교함으로써 RL의 안정성을 강화합니다.
Our perspective.
EFN은 이러한 요소들의 교차 지점에 위치합니다. EFN은 frozen VLA 기반의 post-deployment 상황을 목표로 하며, live experience bank를 유지하고, vision-language joint embedding space에서 task-relevant transition을 retrieval한 뒤, base policy를 보정하는 residual action을 예측합니다. Residual은 retrieval된 transition의 successor와 현재 agent가 만든 next frame을 비교하는 dense similarity-shaped reward로 학습되며, backbone을 업데이트하는 일은 단 한 번도 일어나지 않습니다.
2.3. Embodied Reinforcement Learning
Embodied RL은 물리 또는 시뮬레이션 환경과의 상호작용을 통해 control policy를 학습하며, sparse reward 및 제한된 데이터라는 문제에 직면합니다. 기존 연구에서는 goal relabeling, 대규모 실로봇 데이터 수집, offline dataset을 활용한 사전 학습 후 온라인 개선, pixel 기반 strong regularization, world-model imagination 등 다양한 방식으로 이러한 문제를 해결해왔습니다. 또한 compositional 및 continual embodied learning benchmark는 robustness와 knowledge accumulation 평가의 중요성을 강조합니다.
Our scope.
본 연구는 더 큰 VLA를 새로 학습하는 대신, frozen policy를 강화하는 경량 post-deployment 메커니즘에 초점을 둡니다. 구체적으로 EFN은 Soft Actor–Critic으로 학습되며, retrieval된 trajectory와 현재 observation을 residual action으로 변환하여 controller를 보정하는 역할을 수행합니다. 즉, VLA 자체를 다시 학습하는 것이 아니라, experience-feedback module만을 학습하는 방식입니다.
3. Methodology

3.1. Overview of EFN
EFN은 frozen vision–language–action (VLA) policy를 감싸는 experience-centric controller이며, backbone weight를 업데이트하지 않고도 배치 단계에서 행동을 개선하는 구조입니다. 먼저 step-level experience bank와 rollout-level instruction 및 step-level visual key와 action을 저장하는 record schema를 설계합니다(Section 3.2). 이 bank가 주어지면, EFN은 similarity-shaped reward와 Soft Actor–Critic을 이용해 frozen VLA 위에 residual policy를 학습하며, idling을 억제하기 위한 shaping도 포함합니다(Section 3.3). 배치 단계에서는 모든 network parameter가 freeze된 상태이며, EFN은 instruction-filtered, efficiency-aware retrieval을 수행하고, 매 step에서 학습된 residual correction을 적용하며, 성공한 rollout을 추가하여 bank를 온라인으로 확장합니다(Section 3.4). 따라서 배치 이후의 적응은 gradient update가 아니라 오직 memory의 성장과 recall에서만 발생합니다. Figure 2와 Figure 3은 각각 학습과 배치 단계에서의 EFN을 요약한 것입니다. 이 설계의 근거는 Appendix C에서 설명합니다.
3.2. Experience Bank Design
Storage schema.
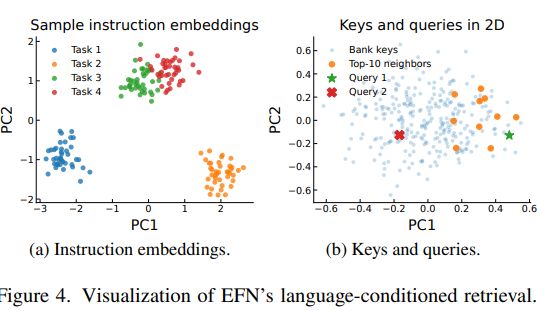
EFN은 rollout $ \tau = (s_1, a_1, \dots, s_T, a_T) $ 단위로 경험을 저장합니다. 수집 또는 배치 과정에서 실제 action이 실행된 모든 step $(s_t, a_t)$을 bank에 기록합니다. Simulator 초기 로딩이나 warm-up 동안의 “blank” step은 제외합니다. 초기 offline bank에는 성공, near-success, 일부 실패 trajectory도 포함되며, 우리의 reward가 binary success가 아니라 semantic similarity 기반이므로 그대로 유지합니다(자세한 내용 Appendix D). 반면 배치 중에는 성공한 trajectory만 추가하며, 이들은 향후 retrieval의 고품질 reference가 됩니다. 각 rollout $ \tau $ 에 대해 episode 시작 시 VLA의 language encoder로 task instruction을 인코딩하여 instruction embedding $ \ell_\tau $를 저장합니다.
각 step에는 다음 세 요소가 저장됩니다:
- VLA vision encoder feature $ F_t \in \mathbb{R}^{L \times C} $
- Retrieval을 위한 compact key vector $ k_t \in \mathbb{R}^{d_k} $
- Base policy가 출력한 raw action $ a_t^{(0)} $
따라서 bank는 다음 tuple을 저장합니다: $ (\ell_\tau, F_t, k_t, a_t^{(0)}) $
Key construction and probabilistic top-𝑘 retrieval.
Key는 per-token ℓ2 normalization을 적용한 뒤 mean–max fusion을 사용하여 retrieval key를 구성합니다.
먼저, $F_t$ 내부의 각 token feature를 채널 방향으로 $ℓ_2$-normalize한 뒤, token dimension을 따라 mean과 max를 계산하고 각각을 다시 normalize합니다:

그 다음, 두 값을 동일 가중치로 평균내고 마지막으로 한 번 더 normalization하여 key를 생성합니다(여기서 $d_k = C$입니다):

Query 시점에서, 현재 frame로부터 동일한 fusion 과정을 거쳐 query vector $q_t$ 를 만든 뒤, 모든 key와의 cosine similarity $s_i = \cos(q_t, k_i)$ 를 계산하고 top-𝑘 인덱스 $N_k(q_t)$ 를 선택합니다.
그 후, 이 shortlist 내에서 similarity-biased 분포로 key 하나를 샘플링합니다:
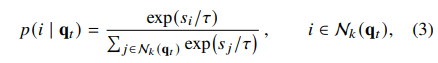
여기서 $ \tau > 0 $ 는 temperature입니다.
이 “retrieve-then-sample” 절차는 가장 유사한 경험을 선호하면서도, 근접한 후보들 사이의 탐색을 유지하도록 설계되어 있습니다. Figure 4는 EFN이 experience bank에서 어떻게 구조를 활용하는지를 보여줍니다. Instruction embedding $ \ell_\tau $ 들은 task 유형별로 cluster를 이루기 때문에 instruction-filtered candidate set $R_n$ 은 작고 집중된 형태가 되며, retrieval된 key들은 시각적 공간에서 각 query 주변의 아주 밀집된 local neighborhood를 형성하게 됩니다.
3.3. Learning with Residual Policy Optimization
Goal and key differences.
EFN은 과거의 관련 있는 experience를 다시 불러오고, 현재 action을 조정하여 다음 observation이 그 경험에서의 “다음에 일어났던 상태”와 유사해지도록 base policy를 미세하게 조정하는 방식으로 학습된다. 시간 $t$ 단계에서 입력은 다음과 같다: 현재의 visual feature $F_t$, base policy의 action $a_t^{(0)}$, 그리고 retrieval된 experience step $(\hat{F}, \hat{a}, \hat{F}^+)$ 및 rollout-level instruction embedding $ℓ$ (retrieval은 이전 subsection에서 정의됨). EFN의 actor는 residual $Δa_t$ 를 출력하며, 실제 실행되는 control은 다음과 같다:
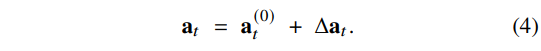
직관적으로, $a_t^{(0)}$ 는 base policy의 기존 능력을 유지하고, $Δa_t$ 는 retrieval된 transition을 조건으로 하는 experience-informed correction 역할을 한다.
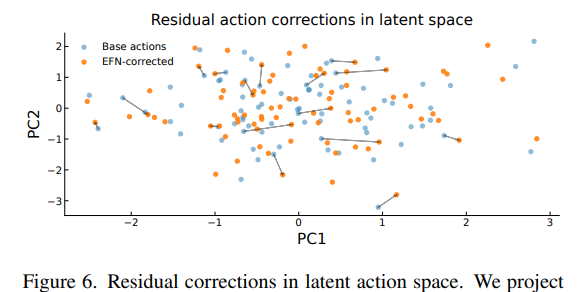
Figure 6은 latent action space에서 EFN의 행동을 시각화한 것이다. Base action $a_t^{(0)}$ 와 EFN이 보정한 action $a_t$ 를 PCA로 2D에 투영하고 residual $Δa_t$ 를 화살표로 표시한다. Residual은 base action 주변의 짧은 변위로 구성되며, EFN이 frozen policy 위에서 이를 완전히 대체하는 controller가 아니라 미세 조정 레이어로 동작함을 보여준다.
Dense Semantic Match Reward.
"retrieved experience의 다음 결과와 일치한다"는 개념을 수치화하기 위해, 실제로 실행된 다음 observation $s_{t+1}$ 을 experience의 successor frame $\hat{s}^+$ 와 semantic 수준에서 비교한다. 앞서 정의한 mean–max fusion $u(\cdot)$ 을 vision feature에 적용해 unit vector를 생성한다. Action $a_t$ 를 실행한 뒤 환경은 vision feature $F_{t+1}$ 을 가진 $s_{t+1}$ 을 반환한다. 우리는 다음의 dense similarity reward를 정의한다:
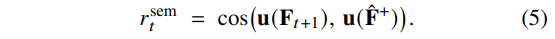
또한 base behavior를 불안정하게 만들지 않도록 residual 크기에 대한 regularization을 추가한다:
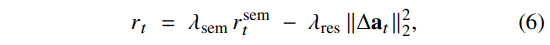
여기서 $\lambda_{\text{sem}}, \lambda_{\text{res}} > 0$ 이다. 이 reward는 supervised residual label을 요구하지 않으며, success/failure 여부가 아니라 feature similarity에 기반하므로 성공·실패 trajectory 모두 의미 있는 state transition을 포함하면 학습에 활용할 수 있다(Appendix D 참고).
SAC objective.
EFN을 Soft Actor–Critic으로 학습하며, actor와 critic은 모두 현재 context와 retrieved experience context를 조건으로 한다.
학습된 context representation은 다음과 같이 정의한다:

(base policy는 frozen 상태)
Stochastic residual policy는 $ \pi_\phi(Δa_t \mid c_t)$ 이며, Q-function $Q_{\theta_1}, Q_{\theta_2}$ 는 corrected action $a_t = a_t^{(0)} + Δa_t$ 를 평가한다. Critic target은 soft Bellman backup으로 정의된다:

Critic loss는 표준 squared error이다:
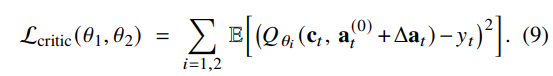
Actor는 entropy-regularized objective를 최소화한다:
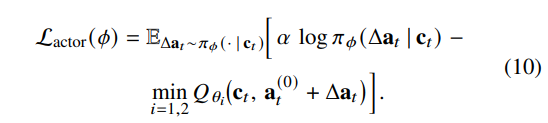
Temperature $α$ 는 target entropy를 유지하도록 조정될 수 있다.
Training 동안 gradient는 retrieval target $\hat{F}, \hat{F}^+$ 로 흘러가지 않으며, 업데이트는 EFN의 actor/critic/context encoder에만 적용된다.
Reward shaping with anti-idling penalty.
Retrieved next observation과의 절대적 일치도를 유지하면서도 “비슷하지만 진전 없음” 상태를 방지하고 rollout 길이를 줄이기 위해, semantic similarity $sim \in [0, 1]$ 을 다음처럼 정의한다:
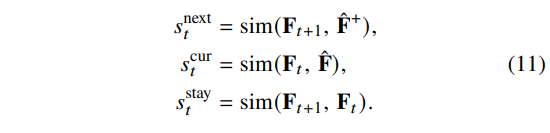
추가적인 항들은 다음과 같이 설정한다 ($[x]_+ = \max(x, 0)$, $ε > 0$):

최종 dense reward는 다음과 같다:
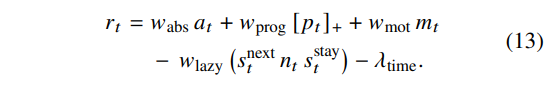
여기서 $w_{\text{abs}}, w_{\text{prog}}, w_{\text{mot}}, w_{\text{lazy}} \ge 0$ , $λ_{\text{time}} \ge 0$ 는 scalar 값이다.
식 (13)은:
- 절대 similarity 보상 $a_t$ 를 유지하고
- retrieved next state로의 실제 “진전”을 보상하며
- trivial motion 방지를 위해 $m_t$ 를 추가하고
- 비슷한 상태에서 거의 이동하지 않는 “idling” 상황에는 penalty를 부여하며
- rollout을 짧게 유지하도록 per-step 비용 $λ_{\text{time}}$ 을 추가한다.
즉, EFN은 residual policy를 학습하여 $F_{t+1}$ 이 $ \hat{F}^+ $ 방향으로 이동하도록 조정한다.
3.4. Deployment Retrieval and Experience Growth
Goal and key differences
배포(deployment) 시 EFN은 base policy와 EFN의 가중치를 업데이트하지 않은 상태에서 과거의 experience를 다시 불러오고 재사용한다. Inference 파이프라인은 학습 과정과 거의 동일하지만 세 가지 측면에서 다르다.첫째, retrieval은 task-filtered 방식으로 수행된다. 즉, 현재 task와 instruction embedding이 가까운 rollout만 매칭 대상으로 제한한다.둘째, 효율적인 rollout을 우선시한다. 더 짧은 trajectory일수록 불필요한 action이 적고 더 빠르게 작업이 완료되므로 선택 우선순위를 높게 부여한다. 셋째, experience bank는 online으로 성장한다. 즉, rollout이 끝나면 그 step들이 bank에 삽입되어 이후 episode에서 재사용된다.
따라서 post-deployment 적응은 gradient update가 아니라 기억(memory)의 성장에만 의존하여 발생한다.
Instruction-filtered candidate set.
Task description이 주어지면, 우리는 VLA의 language encoder로 instruction embedding $ℓ_\star$ 를 계산한다. 이 embedding을 이용해 저장된 rollout-level embedding 집합 ${ℓ_{\tau_j}}$ 과 cosine similarity를 비교하여 상위 $n$개 rollout을 선택한다:

이 rollout들의 모든 step-level entry는 candidate experience set $C$ 를 구성하며, 해당 episode 동안 retrieval은 오직 이 집합에서만 수행된다.
Step-wise retrieval with efficiency prior.
시간 $t$ 에서, 우리는 이전에 정의한 mean–max fusion $u(\cdot)$ 을 사용해 시각적 query $q_t = u(F_t)$ 를 생성한다.
Candidate $i \in C$ 는 key $k_i$, successor feature $\hat{F}^+i$, 그리고 전체 길이 $L{\rho(i)}$ 를 가진 rollout $\rho(i)$ 에 속한다. Candidate의 점수는 semantic similarity와 rollout efficiency prior를 결합해 계산한다.
우선 similarity: $s_i=cos(q_t,k_i)$, 그다음, rollout 길이에 기반한 prior $g(L_{\rho(i)}) \in [0,1]$ 을 정의한다. 이 값은 rollout 길이가 길어질수록 감소한다. 예: $g(𝐿) = exp[−𝛽 𝐿/\bar {L}] $ 종합 점수는 다음과 같다:

상위 $k$개의 후보를 선택한 후 softmax로 하나를 샘플링한다:

여기서 $τ$ 는 temperature, $N_k(t)$ 는 상위 $k$개 후보의 index 집합이다. 이 방식은 near-match 후보들 간의 탐색을 유지하면서 semantic similarity와 efficiency가 모두 높은 memory를 선호하도록 설계되어 있다.
Action correction and execution.
Retrieval된 experience $(\hat{F}_i,; \hat{a}_i,; \hat{F}^+_i)$ 와 현재 context가 주어지면, EFN은 residual $Δa_t$ 를 예측하고 다음과 같은 action을 실행한다:

Inference 동안 critic과 residual policy는 모두 frozen되어 있으며, 실제 실행에서는 variance 감소를 위해 deterministic mean action(또는 temperature가 낮은 sampling)을 사용한다. 개념적으로 residual correction은 다음 observation을 $\hat{F}^+_i$ 방향으로 유도하는 방식이며, 추가 학습 없이도 성공적인 transition을 재활용할 수 있다
Online experience growth.
각 episode가 끝나면 rollout 전체를 experience bank에 저장한다. Episode 수준 instruction embedding $ℓ_\star$ 와 함께, 모든 step tuple 을 mean–max keying scheme을 적용해 기록한다 .
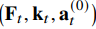
Deployment 시에는 training phase와 달리 성공한(successful) rollout만 bank에 추가한다(Appendix D 참고). 이는 미래 retrieval의 고품질 reference가 된다.
초기 offline bank는 near-success 또는 실패 trajectory도 포함할 수 있다(Appendix D에서도 언급됨). Deployment 환경에서 memory budget이 있을 경우 reservoir sampling 또는 recency-based replacement 같은 보존 전략을 적용할 수 있으며, retrieval/학습 메커니즘은 그대로 유지된다.
4. Experiments
4.1. Experimental setup.
본 연구에서는 Libero benchmark에서 OpenVLA , UniVLA, GO1 세 가지 사전학습된 VLA를 사용하여 EFN을 평가합니다. 모든 모델은 동일한 시각적 전처리(센터 크롭, 256 리사이즈)를 공유합니다. UniVLA는 한 step 당 256개의 visual token과 4개의 latent action token을 제공하며, EFN은 현재 token과 rertrieval된 token을 받아 latent 공간에서 residual을 예측하고 이를 base latent action에 더한 뒤, frozen action head를 사용해 디코딩합니다.
테스트 시 정책은 actor mean에 tanh를 적용하여 deterministic하게 만듭니다. 본 연구에서는 success rate와 성공한 경우에 한해 평균 step 수(작을수록 더 좋음)을 보고하며, horizon은 $H = 320$ 입니다. 평가 시 사용되는 experience bank는 학습과 동일하게 구성하며, pooled visual embedding에 대한 cosine nearest neighbors을 통해 조회됩니다. 각 successful rollout 이후 episode는 bank에 추가되며, 더 짧은 successful episode가 우선시됩니다. 평가 중에는 gradient update는 수행되지 않습니다.
각 backbone에 대해 네 가지 baseline과 EFN variant를 비교하며, 이는 Section 2의 세 가지 패러다임을 구현한 것입니다.\
- kNN-RAG: retrieval-only 방식으로, bank에서 가장 가까운 past step을 retrieval하여 그 action을 그대로 복사하는 비파라메트릭 방법.
- ResAct:residual-only baseline으로, frozen VLA action 위에 additicve correction을 학습하지만, retrieval이나 similarity-shpaed reward는 사용하지 않습니다.
- R2A: retrieval-augmented RL을 VLA에 적용한 방식으로, retrieval 된 trajectory를 조건으로 정책 전체에 end-to-end 업데이트하며 backbone을 수정합니다.
- GC-TTT: goal-conditioned test-time training으로, retrieval된 rollout을 사용해 backbone을 온라인으로 업데이트합니다.
모든 retrieval 기반 방법은 동일한 experience bank와 retrieval 인터페이스를 공유하며, retrieval을 직접 action 복사, residual correction , backbone 업데이트 중 어떻게 사용할지만 다릅니다. EFN은 bank 용량 $Vol \in {300, 1000}$ 으로 평가하며, 이는 task당 최대 저장 transition 수를 의미합니다. 실험은 AgiBot-G1 플랫폼에서 GO-1과 함께 수행되었습니다. Runtime 및 memory overhead는 Appendix E에서 제시하며, frozen VLA forward pass 대비 매우 작다. 각 설정은 50 episode × 3 seeds 로 평균을 보고합니다.
4.2. Benchmark and Analysis
Results on LIBERO.
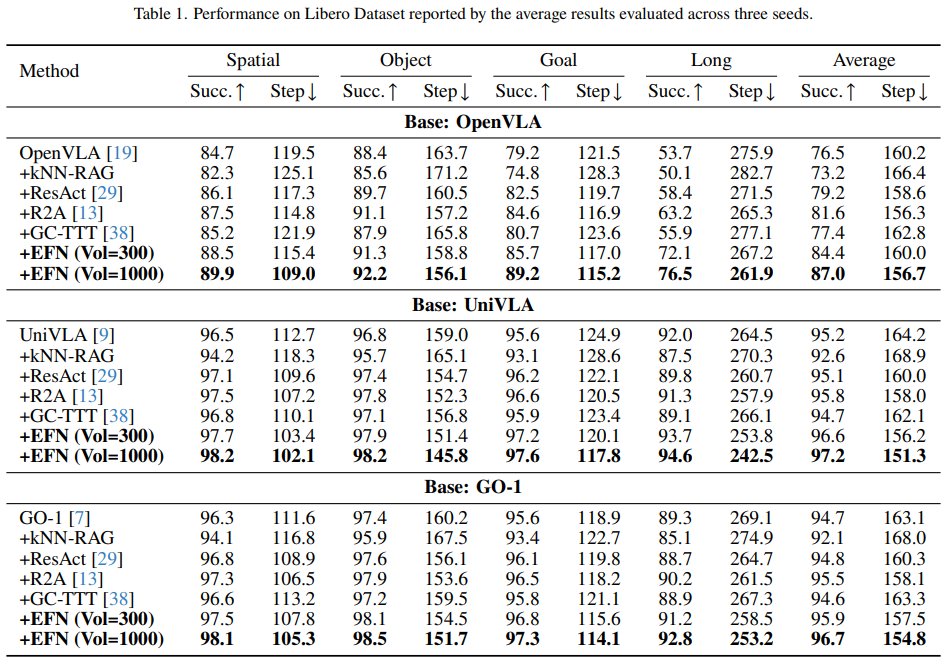

Table 1은 Libero 결과를 요약합니다. 세 backbone모두에서 EFN은 성공률과 효율성 측면에서 frozen VLA 보다 지속적으로 우수한 성능을 보였습니다.
- kNN-RAG는 nearest neighbor action 복사 방식이 매우 불안정하기 때문에, 종종 성능을 약화시켰습니다.
- ResAct는 residual refinement 덕분에 소폭의 개선은 있었으나, episodic context가 없어 한계가 있었습니다.
- R2A는 retrieval-augmented RL이므로 성능 향상은 있었으나 backbone을 업데이트 하기 때문에 비용이 크며, 동일한 interaction budget에서는 EFN보다 낮은 성능을 보였습니다.
- GC-TTT는 on-i.i.d. rollout에서 backbone을 공격적으로 업데이트하기 때문에 작은 혹은 음의 성능 향상을 보였습니다.
EFN은 작은 bank ($Vol=300$)에서도 이미 모든 baseline을 능가하거나 동일한 성능을 나타내며, $Vol=1000$은 추가적인(하지만 소폭의) 이득을 제공합니다. Figure 7은 EFN의 residual action이 어떻게 base policy 출력을 보정하는지 보여줍니다.
Real-world results.
Table 2는 GO-1을 탑재한 AgiBot-G1에서 네 가지 실제 작업(BottlePlace, ShelfSort, StockLift, DrawerStore) 결과를 보여줍니다. 시뮬레이션과 동일한 경향이 나타났습니다:
- kNN-RAG 는 일관되게 성능을 크게 떨어뜨림
- ResAct, R2A 는 중간 수준의 개선
- GC-TTT 는 불안정하며 가장 어려운 작업에서는 실패
- EFN 은 가장 높은 성공률과 더 적은 step 수를 기록
또한 실험 환경에서는 $Vol=300$ 과 $Vol=1000$ 의 차이가 시뮬레이션보다 작았으며, 이는 moderate bank만으로도 주요 task variation을 포괄하기 충분함을 의미합니다. 모든 EFN 결과는 frozen GO-1 backbone으로 수행되며, 적응은 오직 experience bank와 residual head에 의해서만 발생합니다. 반면 R2A와 GC-TTT는 backbone 업데이트를 필요로 합니다.
4.3. Ablation Study
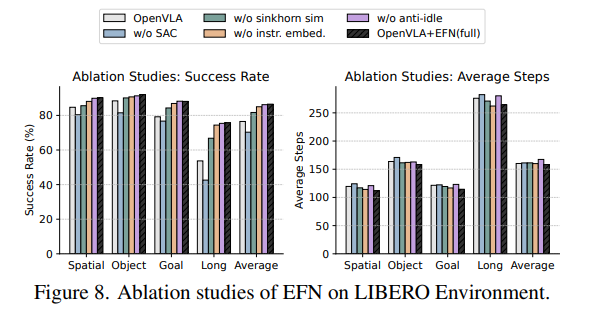
LIBERO에서 네 가지 제어된 ablation variant를 평가하였습니다(Figure 8).
- Effect of SAC.
SAC 제거(w/o SAC)는 성공률과 효율성 모두를 악화시키며, entropy-regularized 최적화의 필요성을 보여줍니다. - Effect of dense rewards.
similarity-shaped dense reward를 제거(w/o dense)하고 sparse task return만 사용할 경우 학습이 느려지고 최종 성능이 감소하였습니다. - Effect of instruction.
instruction-level filtering 제거(w/o instr)는 성능을 저하시켰으며, instruction-aware retrieval이 중요함을 보여줍니다. - Effect of anti-idle.
anti-idling term을 제거(w/o anti-idle)하면 성능이 감소하였으며, 이는 idleness penalty가 의미 있는 역할을 함을 의미합니다. - Effect of residual-action.
residual correction을 제거하고 직접 action을 예측하도록 한 경우 성능이 떨어졌습니다. 이는 base policy의 generalization 능력을 버리고 lightweight actor에게 full action space를 전부 모델링하게 하는 것이 문제임을 Appendix E에서 설명합니다.
Inference time.
흥미롭게도, EFN은 성능을 향상시키는 동시에 효율성 역시 개선되었습니다. 각 step에서 약 4.2% latency 증가가 발생하지만, episode 길이는 11.5% 감소하여 결과적으로 전체 episode 시간은 7.9% 감소했습니다. 즉, EFN은 더 높은 성공률을 달성하면서도 더 효율적으로 작동합니다.
5. Conclusion
본 논문에서는 Experience Feedback Network(EFN)을 소개하였습니다. 이는 frozen vision–language–action policy를 experience bank와 residual module로 보강하는 retrieval-conditioned 방식입니다. EFN은 joint vision-language 공간에서 task-relevant transition을 retrieval하고, similarity-shaped reinforcement learning을 통해 residual controller를 학습하여 backbone finetuning 없이도 post-deployment 적응을 가능하게 합니다.
LIBERO와 실제 AgiBot-G1 플랫폼에서 EFN은 동일 backbone과 interaction budget 조건에서 retrieval-only, residual-only, retrieval-augmented RL, test-time training baseline을 지속적으로 능가했습니다.

