논문 주소: https://openreview.net/pdf?id=aT4LG8c6DE
Abstract
대규모 Vision-Langauge-Action 모델은 자연어 지시를 로봇 action으로 매핑하는 데 탁월합니다. 그러나 이러한 모델은 일반적으로 action을 종단 출력으로 취급하며, imitation learning은 종종 execution bias를 초래하고 동적 supervision이나 online error correction을 위한 매커니즘이 부족합니다. 한편, World model은 predictive reasoning에서 가능성을 보여왔지만, 기존 접근법은 대체로 긴 시퀀스에 대해 프레임 단위로 연속적인 rollout을 요구하여 높은 계산 비용과 제한된 유연성을 초래합니다. 본 연구에서는 기본 VLA policy를 보정하기 위한 online intervention 매커니즘을 도입하는 새로운 프레임워크인 VLA-in-the-Loop를 제안합니다. 본 연구의 핵심 혁신은 연속적인 state prediction이 아닌 on-emand 방식의 event-triggered “corrector”로서 경량의 composite World Model을 사용하는 데 있습니다. VLA가 high-stakes action 예: gripper를 닫는 동작)을 제안할 때, 이 임계 시점에서 composite WM은 먼저 discriminative component를 사용하여 해당 action의 feasibility를 평가합니다. 제안된 action이 실행 불가능하다고 판단될 경우, generative model이 현재 state로부터 성공적인 미래 trajectory에 대한 짧은 비디오를 합성합니다. 로봇은 inverse dynamics model(IDM)에 의해 디코딩된 action을 사용하여 올바른 위치로 유도되며, 보정되고 더 강건한 action을 실행합니다. 이 plug-in 구조는 계산 효율적일 뿐 아니라, 잠재적 failure로부터 학습함으로써 데이터 활용도를 향상시키고, onlinme disturbance에 대한 VLA 모델의 강건성을 유의미하게 개선합니다. 본 연구에선 시뮬레이션과 실제 환경 모두에서 다수의 로봇 grasping task에 걸쳐 본 프레임워크를 검증하였으며, world model을 단순한 prediction 도구가 아니라 VLA 기반 로봇 시스템에서 실시간 보정을 수행하는 능동적 주체로 활용하는 효과를 입증합니다.
1 INTRODUCTION
Vision-Language-Action 모델은 로봇 조작을 위한 강력한 패러다임으로 부상하였으며, 에이전트가 자연어 지시를 해석하고 시각적 입력으로부터 이에 대응하는 action을 생성할 수 있도록 합니다. 이러한 성공에도 불구하고, 이러한 시스템은 positive grasp 데이터에 대한 imitation learning에 크게 의존하며, action 생성을 종단 단계로 취급하고 동적 supervision이나 online correction을 위한 매커니즘이 부족합니다. 이는 특히 작은 perturation이 치명적인 실패로 이어질 수 있는 동적이거나 모호한 환경에서 execution bias를 초래하는 경우가 많습니다.
VLA의 발전과 병행하여, world model은 환경의 동역학을 모델링하고 predictive reasoning을 지원하는 능력으로 상당한 주목을 받아왔습니다. 미래 state를 시뮬레이션함으로써, 이러한 모델은 에이전트가 결과를 예측하고 그에 따라 계획을 수립할 수 있도록 합니다. 그러나 기존 방법들은 일반적으로 미래 state를 생성하기 위해 연속적인 프레임 단위 rollout에 의존하며, 이는 실시간 제어이는 비현실적인 계산 비용이 큰 과정입니다. 또한 기존 모델들은 실행 중 의사결정을 능동적으로 유도하기보다는, 학습 단계에서 보조적인 supervision 신호로 수동적으로 사용되는 경우가 많습니다.
두 패러다임의 한계를 해결하기 위해, 본 연구에서는 다음과 같은 질문을 던집니다. 만약 에이전트가 중요한 순간에 잠시 멈추어 자신의 계획의 feasibility를 평가하고, 잠재적으로 결함이 있는 action을 실행하기 전에 성공으로 이어지는 trajectory를 상상할 수 있다면 어떨까? 본 연구에서는 Online Policy Rectification을 위한 프레임워크인 VLA-in-the-Loop를 제안하며, 이는 VLA의 일반화된 능력과 경량의 event-driven world model의 predictive power를 시너지적으로 결합합니다. 본 연구의 접근법은 현재 로봇 조작 파이프라인의 두 가지 핵심 한계를 해결하도록 설계되었습니다. (1) Grasping failure를 실시간으로 강건하게 감지하고 대응하지 못하는 문제, (2) corrective action을 유도하는 데 있어 world model의 활용성이 충분하지 않다는 점입니다. 구체적으로, 본 방법은 먼저 primany VLA를 사용하여 현재 visual frame이 grasping에 적합한 keyframe인지 여부를 평가합니다. 이 시점에서, 본 프레임워크는 먼저 discriminative module을 활용하여 제안된 action에 대한 failure 가 감지되면, generative module이 현재 state로부터 성공적인 grasp에 대한 짧은 비디오를 "상상"합니다. 이렇게 상상된 성공 trajectory는 다시 VLA로 loop-back되어, 더 정확하고 보정된 action을 생성하기 위한 명확한 시각적 가이드로 사용됩니다.
이 "in-the-loop"구조는 시너지와 효율성을 목표로 설계되었습니다. 필요할 때만 WM을 활성화함으로 써, 연속적인 prediction에 따른 계산 오버헤드를 회피합니다. 더 나아가 잠재적 failure로 부터 학습함으로써 데이터 효율성과 강건성을 향상시킵니다. 본 연구의 기여는 다음과 같습니다:
- Vision Language Action 모델과 world Model을 새롭고 효율적으로 통합하는 방법을 제안하며, WM은 grasp action이 예측될 때만 선택적으로 활성화되는 경량의 event-driven plug-in으로 동작합니다. 이 설게는 연속적인 rollout에 따른 비용을 발생시키지 않으면서 실시간 보정을 가능하게 합니다.
- 본 프레임워크는 world model을 grasp correction에 적용한 최초의 연구로, graspability를 평가하는 discriminative ability와 단일한 미래의 graspable state를 예측하는 generative capacity를 활용함으로써, 기존 방법에서 사용되던 연속적이고 자원 집약적인 생성을 회피합니다.
- 성공 및 실패 실행을 모두 활용하여 강건한 decision boundary를 학습하는 failure-driven training 전략을 world-model에 도입합니다. 이는 데이터 효율성과 일반화를 개선하며, online intervention과 환경적 disturbance에 대한 강한 강건성을 보이는 다수의 robot grasping benchmark에서 state-of-the-art 성능을 달성합니다.
2 RELATED WORKS
Vision-Language-Action (VLA) Models
Vision과 Language를 로봇 제어에 통합하려는 연구는 VLA 모델의 개발로 이어졌으며, 이는 로봇이 multimodal 입력을 해석하고 context-aware action을 생성할 수 있도록 합니다. VIMA와 같은 초기 연구는 하나의 거대한 네트워크가 다양한 task를 처리할 수 있는 가능성을 보여주었습니다. 이후 RT-1과 RT-2와 같은 보다 특화된 로봇 모델들이 등장하여, Vision Language model을 로봇 데이터에 co-fining함으로 써 web-scale의 추상적 지식을 물리적 제어로 전이할 수 있음을 보였고, 인상적인 zero-shot generalization을 가능하게 했습니다. 최근에는 CogVLM, CogACT와 같은 연구들이 더 강력한 vision encoder를 통합하여 모델의 지각적 이해 능력을 더욱 향상시켰습니다. 그러나 이러한 모델들은 일반적으로 imitation learning에 의존하며 action 생성을 종단 출력으로 취급하기 때문에, 동적 환경에서의 적응성이 제한되고, 보지 못한 상황에서 발생하는 online error accumulation 문제는 여전히 중요한 미해결 과제로 남아 있습니다. 본 연구는 VLA 아키텍처 자체를 변경하는 방식이 아니라, 외부의 지능적인 correction loop를 추가함으로 써 이러한 한계를 직접적으로 해결하고자 합니다.
World Models in Robotics
World model은 환경의 예측 모델을 학습하여, 현재 observation과 action으로부터 미래 state를 시뮬레이션하고 그에 따라 계획을 수립할 수 있도록 합니다. PalNet과 Dreamer 계열의 대표적인 연구들은 학습된 latent space 안에서 “dreaming” 혹은 planning을 수행함으로써 에이전트가 복잡한 행동을 학습할 수 있음을 보여주었습니다. WorldVLA은 VLA와 world model을 하나의 프레임워크로 통합하려는 시도를 통해 joint training의 상호 이점을 강조 하였습니다. 그러나 이러한 모뎰들은 일반적으로 offline planning을 위해 미래 state를 연속적이고 단계별로 예측해야 하며, 주로 학습 과정에서 추가적인 supervision 신호를 제공하는 보조 헤드로 사용될 뿐, 강력한 policy의 online correction을 능동적으로 유도하지는 않습니다. 또한, failure recovery를 위한 명시적인 메커닞므이 부족합니다. 본 연구의 핵심적인 차별점은 WM의 구성 요소인 generation과 discrimination을 on-demand, event-triggered intervention에 재활용 함으로써, 지속적인 미래 시뮬레이션에 따른 오버헤드를 회피하는 데 있습니다.
Online Policy Correction and Intervention
Online correction의 개념은 동적 환경에서 로봇을 배치하는 데 있어 핵심적인 요소입니다. 기존의 grasping 파이프라인은 실패가 발생했을 때 정적인 policy 및 인간의 개입에 의존하는 경우가 많아, 동적이거나 모호한 환경에서의 적응성이 제한됩니다. 최근에는 Large Vision-Language Model의 reasoning 능력을 활용하여, 로봇이 실패한 grasp 시도를 반성하고 전략을 조정하도록 하는 프레임워크를 제안하여, 고수준의 의미적 피드백을 세밀한 action correction으로 변환함으로써 조작 오류로부터의 정밀한 복구를 가능하게 합니다. 그러나 이러한 방법들은 인간의 감독이 필요하거나, 잠재적으로 매우 다양한 failure mode에 대해 일반화하는데 한계를 가지고 있습니다. 이에 비해 본 프레임워크는 world model의 predictive power를 활용한 능동적이고 perceptually-grounded self-correction loop를 도입합니다. Discriminative evaluation과 generative prediction을 결합함으로써, 본 시스템은 graspability를 평가하고 미래의 graspable state를 경량이면서도 목표 지향적인 방식으로 시뮬레이션할 수 있습니다.
3 METHODOLOGY
본 연구에서 제안하는 방법인 VLA-in-the-Loop는 World Model의 개념을 재목적화하여, 중요한 의사 결정 시점에서 기본 VLA policy를 보정하기 위한 새로운 online intervention 메커니즘을 활용합니다. 기존의 접근법에서 WM이 미래 state를 지속적으로 예측하는 것과 달리, 본 방법은 discriminative 능력과 generative 능력을 결합한 경량의 composite WM을 on-demand 방식의 "corrector"로 사용합니다. 본 절에서는 먼저 online correction 문제를 정식화하고, 이어서 VLA-in-the-Loop 프레임워크를 설명한 후, composite world model의 구체적인 구성 요소 설게를 상세히 기술합니다.
Problem Formulation
본 절에서는 로봇 조작 task를 Partically Observable Markov Decision Process(POMDP)로 정식화합니다. Observation space를 O라 할 때, 각 timestep t에서 에이전트는 시각적 observation $o_t = (I_t, s_t) \in O$를 받으며, 이는 RGB image $I_t \in I$와 proprioceptive state $s_t \in S$(예: end-effector pose, gripper state)를 결합한 것입니다. 사전 학습된 VLA는 expert dataset $D_{expert} = {(o_i, a_i)}{i=1}^N$에 대해 behavioral cloning으로 학습된 policy $\pi{VLA}(a_t \mid o_t, L)$를 제공하며,observation과 language instruction L에 조건화된 low-level action $a_t = (\Delta xyz_t, \Delta rpy_t, g_t)$를 출력한다. 여기서 $(\Delta xyz_t, \Delta rpy_t)$는 Cartesian 및 orientation increment를 의미하고, $g_t$는 gripper command(open/close)를 나타냅니다. 학습 목표는 expert action과의 편차를 최소화하는 것입니다:

실제 배포 단계에서의 핵심 문제는 covariate shift로, online observation 분포 $P_{online}(o)$가 학습 분포 $P_{expert}(o)$와 달라지는 현상입니다. 이로 인해 $\pi_{VLA}$의 성능이 저하되며, 기대 보상 $\mathbb{E}{\tau \sim \pi{VLA}} [\sum_t R(s_t, a_t)]$이 허용 가능한 임계값 이하로 떨어지게 됩니다.
이를 해결하기 위해 본 연구에서는 online correction function C를 도입하여, VLA가 제안한 action $a_t = \pi_{VLA}(o_t, L)$을 조절하고 최종 action $a'_t = C(o_t, a_t)$를 생성합니다. World Model을 C로 구현하여, 성공적인 trajectory로 policy를 유도하도록 지능적으로 개입하며, 필요할 때만 C를 호출함으로써 계산 오버헤드를 최소화합니다. 이는 다음과 같이 표현됩니다.
$\max_C ; \mathbb{E}{\tau \sim \pi'} \left[ \sum{t=0}^{T} R(s_t, a'_t) \right]$
3.1 BASE POLICY: KEYFRAME DETECTION VIA PRIMARY VLA
프레임워크의 첫 단계는 CogACT와 같은 사전 학습된 VLA 모델을 base policy로 활용하여 초기 action $a_t = (\Delta xyz_t, \Delta rpy_t, g_t)$ 을 생성하는 것입니다. Grasping과 같은 조작 task에서 가장 결정정인 순간은 grasp을 시작하는 시점입니다. 따라서 본 연구에서는 base VLA policy가 gripper state를 "close"로 전이시키는 action을 제안하는 timestep t를 keyframe trigger로 정의합니다. 이 시점에서 supervisor가 제어를 넘겨 받아 discrimination module $D_t$를 사용해 제안된 action의 성공 가능성을 평가합니다. 반면, arm 이동이나 gripper open과 같은 다른 action의 경우에는 supervisor가 개입하지 않으며, VLA가 예측한 action을 그대로 실행합니다.
3.2 INTERVENER: A COMPOSITE WORLD MODEL

본 연구에서의 WM은 단일한 dynamics predictor가 아니라, feasibility를 평가하는 VLM 기반 discriminator와 correction을 상상하는 video-generative model로 구성된 composite 시스템입니다.
The Discriminator: Is This Grasp Feasible
Discriminative module $D_t$는 강력한 Vision-Language Model을 사용해 구현되며, 본 연구에서는 fine-tuned Qwen-VL 2.5를 사용합니다. Failure prediction task는 Visual QnA문제로 정식화됩니다. 데이터 집약적인 binary classifier를 별도로 학습하는 대신, 모듈은 현재 observation $o_t$와 구조화된 text prompt를 입력으로 받습니다. 예를 들어, “Query: My task is ‘Stack Green Block on Yellow Block’, Should the robot arm close its gripper in the next step?”과 같은 형식입니다. 모델 $M_{disc}$는 성공 및 실패 grasp 사례로 구성된 데이터셋으로 학습되며, $D_t \in {\text{Suitable}, \text{Unsuitable}}$ 중 하나를 출력하도록 학습됩니다. 이는 다음과 같이 표현될 수 있습니다:
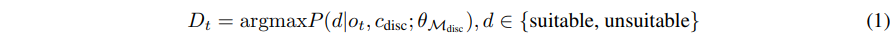
이러한 VQA 정식화는 VLM이 사전 학습된 object property, spatial relationship, physical affordance에 대한 풍부한 지식을 활용하여 제안된 grasp의 feasibility를 판단할 수 있도록 합니다.
The Generator
Discriminative component가 latent failure($d_t = \text{unsuitable}$)를 감지하면, 시스템은 k step 이전으로 state rollback을 수행하여 보다 안정적인 observation $o'{t}$를 복원하며, 이때 $t' = t - k$ 입니다. 이후 Generative Model $M{gen}$을 활성화하며, image-to-video diffusion model(WAN2.1 등)을 사용하게 됩니다. Generator는 observation $o'{t}$와 “Show the successful grasp of ‘Pick up the apple’ starting from this view.”와 같은 high-level goal $c{gen}$을 입력으로 받아, 성공적인 trajectory를 묘사하는 짧고 물리적으로 타당한 video sequence $V_{succ} = (o'{t}, o'{t+1}, \dots, o'_{t+T})$를 합성합니다. 이 생성 과정은 다음과 같은 조건부 샘플링으로 표현됩니다:
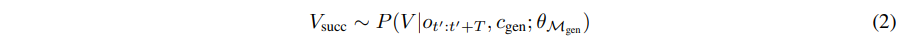
3.3 VLA-IN-THE-LOOP FOR ACTION REFINEMENT
프레임워크의 마지막이자 가장 중요한 단계는 생성된 정보를 policy로 다시 되돌려 corrective loop를 닫는 것 입니다. 본 연구에서는 상상된 성공 video $V_{succ}$를 새로운 강력한 visual context로 사용하여, 업데이트된 VLA policy $\pi'_{VLA}(a't \mid o't \in V{succ}, L)$를 생성합니다. 자원 효율성을 극대화하기 위해, discriminative module $M{disc}$는 behavior parser 역할도 겸하며, weight를 공유하는 최종 VLA로 사용됩니다. 이는 evaluator와 actor라는 두 역할에 대응하는 서로 다른 QA 형식으로 학습하는 multi-task QA training scheme를 통해 구현됩니다. 이러한 “VLA-in-the-loop” 구조는 판단과 행동 사이의 결합을 강화하여, 성공 가능성이 크게 향상된 refined action을 생성합니다.
3.4 TRAINING OBJECTIVES
본 프레임워크는 rectification 과정의 각 단계를 감독하기 위해 설계된 composite training objective를 통해 전체적으로 최적화됩니다. Base VLA policy의 경우 추가적인 supervision loss는 필요하지 않다. $L_{act}^{corrected}$는 상상된 미래에 조건화된 이후 refined action이 corrective path를 정확히 따르도록 보장합니다. 동시에 world model의 각 구성 요소도 이에 맞게 학습됩니다. Discriminative VLM은 keyframe classification task를 위해 binary cross-entropy loss $L_{disc}$로 감독되며, generative video model은 상상된 성공 trajectory의 충실도를 보장하기 위해 reconstruction loss $L_{gen}$로 학습됩니다.
4 EXPERIMENTS
4.1 EXPERIMENTAL SETUP
Experimental Platforms
실제 환경 검증을 위해 Xiaomi Robot(7-DoF)과 ALOHA(6-DoF) 두 가지 플랫폼을 사용하여 RTX 3090 GPU 하나로 태스크당 32회 실험을 수행했습니다. 시뮬레이션은 SIMPLER와 LIBERO 환경에서 WidowX, Google Robot, Franka 세 가지 로봇 암을 사용하여 평가했습니다.
Initial VLA policy
초기 정책은 사전 학습된 CogACT 모델을 미세 조정 없이 사용합니다. 이는 성공 데이터 수집 비용을 아끼기 위함이며, 대신 실패 데이터를 활용해 보정용 월드 모델을 학습시키는 데 집중했습니다. 이 정책은 15-step의 미래 액션을 예측하여 보정의 기초로 삼습니다.
World Model Training
본 연구에서의 world model은 discriminator와 generator로 구성됩니다. Discriminator의 경우, demonstration으로부터 중요한 keyframe을 수동 및 반자동 방식으로 labeling하여 grasping에 ‘suitable’ 또는 ‘unsuitable’한 상태로 구분한 targeted dataset을 구축하였습니다. 이 dataset은 BridgeV2의 일부에서 추출한 100k frame과 실제 환경에서 수집한 2k frame으로 구성되며, positive와 negative sample의 비율은 1:1로 균형을 맞추었습니다. ‘Unsuitable’ state는 gripper state가 grasp를 의도하지 않거나 grasp가 불가능함을 나타내는 trajectory로 정의됩니다. Unsuitable state가 감지되면, 로봇 arm은 기본값 20 step의 m step rollback을 수행하여 새로운 observation을 획득합니다. Generation model의 경우, BridgeV2 dataset에서 33k video clip을 사용하였습니다. 실제 환경 fine-tuning을 위해서는, Xiaomi Robot과 ALOHA에서 각각 100개씩 총 200개의 성공적인 grasping video를 수집하였으며, 각 video는 5–20 frame으로 구성됩니다.
VLA-in-Loop policy finetuning
성공적인 grasping video를 입력으로 받아 corrected action을 출력하도록 unified VLA-in-Loop 모델을 fine-tuning하기 위해 custom VQA dataset을 구성하였습니다. 각 frame의 ground truth action은 해당 source dataset에서 가져옵니다. 학습 과정에서는, 생성된 각 video에서 key grasp-time 주변의 frame 5개를 무작위로 선택하여 모델이 action sequence를 예측하도록 합니다. 자원 사용을 최적화하기 위해, VLA-in-Loop 모델(IDM 역할)과 discriminator 모델(evaluator 역할)을 공동 학습할 수 있는 복합적인 QA pair 구조를 사용합니다. 모델은 observation sequence $O_{t'}^{t'+T}$와 text prompt L을 입력으로 받아 action sequence $a_{t'}^{t'+T}$를 출력하며, 기본 action horizon은 $T=5$로 설정합니다.
4.2 EVALUATION PERFORMANCE

VLA-in-Loop 프레임워크의 효과성, 효율성, 그리고 실제 환경 적용 가능성을 종합적으로 검증하기 위해, 표준화된 시뮬레이션 환경과 실제 로봇 플랫폼 모두에서 광범위한 실험을 수행하였다. 전체 처리 과정의 시각화는 Figure 4에 제시됩니다.
Evaluation on Simulation
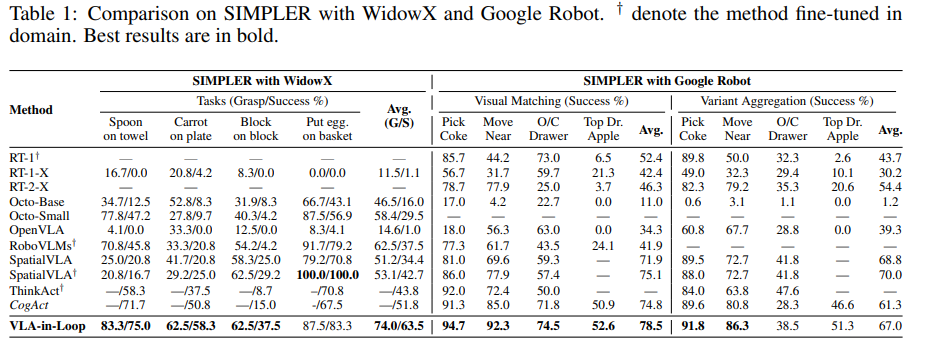
SIMPLER 환경(WidowX)에서 본 방법은 평균 63.5%의 성공률을 기록해 2위인 CogAct(51.8%)를 크게 앞섰습니다. 특히 스푼 놓기나 블록 쌓기처럼 정밀함과 공간 추론이 동시에 필요한 태스크에서, 미세한 오차를 온라인으로 보정하며 뛰어난 성능을 보였습니다.
Google Robot 환경에서도 RT-1 등 비교 모델들을 상회하며 강력한 성능을 유지했습니다. 이는 추가적인 도메인 학습 없이도 서로 다른 로봇의 기구학적 특성에 맞춰 미세한 보정 전략을 적응적으로 적용할 수 있음을 증명합니다.
Real-World Set Up
실제 환경의 노이즈와 변수 속에서도 보정 프레임워크는 단순 그립 성공을 넘어 최종 태스크 성공률을 크게 높였습니다. 보정된 궤적이 더 견고한(high-quality) 그립을 만들어내어, 잡은 후 놓치는 등의 불안정함을 해소했기 때문입니다.
4.3 PROCESSING OF FAILURE PREDICTION AND CORRECTION


정성적 failure correction 예시와 정량적 robustness test를 통해 본 방법의 효과를 입증합니다. Figure 4는 end-to-end correction pipeline을 보여주며, base VLA에서 실패한 grasp가 식별되고(Critic), state rollback이 수행된 뒤, world model이 성공적인 image frame을 상상하여 생성하고(Generation), corrected action이 성공적으로 실행되는 과정을 나타냅니다. Robustness를 평가하기 위해 task 수행 중 제어된 perturbation을 도입하였습니다. (Figure 5). 단순히 실패하거나 중단되는 baseline과 달리, 본 프레임워크는 간섭이 증가하는 상황에서도 유의미하게 더 높은 success rate를 유지합니다. 이는 단순한 passive failure detection이 아니라, proactive하고 generative한 correction을 통해 online disturbance를 효과적으로 처리할 수 있음을 보여줍니다.
4.4 ABLATION STUDY
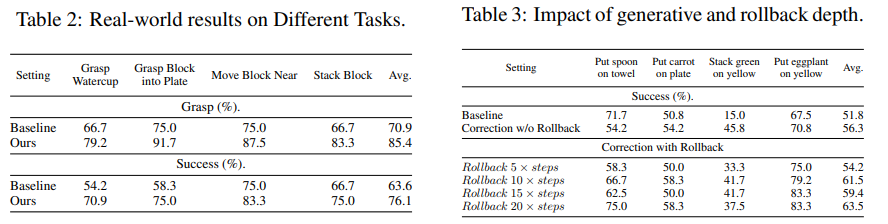
프레임워크의 핵심 구성 요소 기여도를 분석하기 위해, 네 가지 도전적인 task에 대해 ablation study를 수행하였습니다. Table 3에 제시된 결과는 generative correction과 state rollback 메커니즘의 영향을 체계적으로 평가합니다. 분석 결과 두 가지 핵심적인 통찰을 얻었습니다. 첫째, Baseline VLA policy를 성능의 하한선으로 설정하였습니다. Correction w/o Rollback 설정에서는 failure가 예측된 즉시 상태에서 supervisor가 policy를 보정하려 시도합니다. 그러나 이 경우 성능 향상은 미미하거나 일관되지 않았습니다. 이는 failure가 임박한 시점에서는 이미 상태가 회복 불가능해졌을 가능성이 높아, 해당 시점에서의 correction 효과가 제한됨을 시사합니다. 둘째, rollback depth를 5, 10, 15, 20 step으로 변화시키며 Correction with Rollback의 효과를 분석하였습니다. 그 결과, rollback depth가 증가할수록 task success rate가 전반적으로 향상되는 명확한 경향을 확인하였습니다. 더 이른 “건강한” 상태로 되돌아갈수록 generative model이 성공적인 trajectory를 상상할 수 있는 더 나은 출발점을 제공받기 때문입니다. 이는 state rollback이 near-failure 상태에서 벗어나 성공적인 행동을 재계획하는 데 필수적인 구성 요소임을 확인해줍니다. 다만 일정 depth 이후에는 성능 향상이 포화되는 경향을 보이며, 이는 회복 가능한 상태 탐색과 task 진행 유지 사이의 trade-off를 시사합니다.
5 CONCLUSION AND LIMITATION
본 논문에서는 on-demand, online correction을 통해 VLA의 강건성을 향상시키는 프레임워크인 VLA-in-the-Loop를 제안하였습니다. 본 연구의 핵심 기여는 discriminative reasoning과 generative imagination을 결합한 composite world model을 효율적으로 활용하여, 중요한 순간에 policy를 보정하는 새로운 접근법입니다. 이는 보다 신뢰 가능하고 적응적인 로봇 에이전트로 나아가는 기반을 마련합니다. 향후 연구에서는 generative model의 latency를 줄이고, 상상된 trajectory의 물리적 타당성을 더욱 향상시키는 방향을 탐구할 수 있습니다. 또한 더 다양한 task로 프레임워크를 확장하고, 에이전트가 언제 intervention을 트리거해야 하는지를 학습하는 방법도 연구할 계획입니다. 궁극적으로 본 패러다임은 대규모 policy와 foundation model의 on-demand reasoning 능력을 시너지적으로 결합하여, 스스로를 지능적으로 보정하는 로봇 시스템으로 나아가는 방향을 제시합니다.