논문 주소: https://arxiv.org/pdf/2509.23655
Abstract
Vision-Language-Action (VLA) 모델은 대규모로 로봇 조작을 학습하기 위한 핵심적인 접근 방식으로, 사전 학습된 대규모 Vision-Language Models (VLM)을 재활용하여 로봇 행동을 출력하도록 설계됩니다. 그러나 VLM을 로봇 도메인에 적응시키는 과정은 높은 계산 비용을 수반하며, 이는 시각 입력에 대한 tokenization 방식에서 기인한다고 볼 수 있습니다.
본 연구에서는 VLA 학습을 보다 효율적으로 수행하기 위한 Oat-VLA를 제안합니다. Oat-VLA는 VLA를 위한 Object-Agent-centric Tokenization 방식으로, object-centric representation learning의 통찰을 기반으로 장면 내 객체와 에이전트 자신의 시각 정보에 대한 inductive bias를 도입합니다. 그 결과, Oat-VLA는 성능 저하 없이 visual token의 수를 단 몇 개의 token으로 대폭 감소시킬 수 있음을 확인합니다.
또한 Oat-VLA는 LIBERO benchmark suite에서 OpenVLA 대비 최소 두 배 이상 빠르게 수렴하며, 다양한 real-world pick-and-place task에서도 OpenVLA를 능가하는 성능을 달성함을 보입니다.
1 Introduction

Multimodal capability는 robotics을 포함한 real-world application의 핵심 요소입니다. 최근 Vision-Language-Action (VLA) 모델은 일반적인 지식을 imitation learning setting으로 적응시킬 수 있는 능력 덕분에 큰 주목을 받고 있습니다. VLA는 일반적으로 환경에 설치된 camera로부터의 image와 language instruction과 같은 text를 입력으로 받아 robotic action을 예측하며, 이를 통해 로봇 조작에서의 multimodal prompting을 가능하게 합니다. 이러한 성과에도 불구하고, VLA는 새로운 task에 일반화하기 위해 Open X-Embodiment 와 같은 특수한 robotics dataset에 대한 고비용 사전 학습에 의존하고 있습니다. 그러나 이러한 규모의 VLA 학습은 막대한 계산 자원을 요구하며, 이는 많은 연구실에서 현실적으로 접근하기 어렵습니다.
본 연구에서는 최신 state-of-the-art VLA에서의 visual processing이 VLA 학습 비용을 크게 증가시키는 주요 병목 중 하나임을 지적합니다. 이 과정은 일반적으로 image를 수백 개의 patch로 분할한 뒤 , 이를 visual encoder model로 처리하고, 그 출력을 visual token으로 변환하여 LLM에 입력하는 방식으로 구성됩니다. Figure 1에서 보이듯이, 지금까지 가장 널리 사용되어 온 이 visual tokenization 방식은 로봇 작업 성능을 저하시키지 않으면서도 근본적으로 더 효율적인 형태로 개선될 수 있습니다. 본 연구의 핵심 통찰은 language instruction이 주어진 상황에서 task를 수행하기 위해서는 scene 전체가 아니라 관심 객체(object of interest)와 같은 특정 영역에 집중하는 것이 중요하며, 배경 정보는 상대적으로 중요도가 낮아 축소하거나 무시할 수 있다는 점입니다.
이에 본 연구에서는 VLA를 위한 Object-Agent-centric Tokenization scheme, 즉 Oat-VLA를 제안합니다. Oat-VLA는 장면 내에서 중요한 부분만을 선택적으로 tokenization하여, 축소된 수의 visual token으로 VLA에 입력합닌다. 더 적지만 의미적으로 풍부한 token을 생성함으로써, Oat-VLA는 memory 사용량과 계산 비용을 크게 감소시킵니다. 또한 Oat-VLA의 architecture는 OpenVLA에 이미 내재된 사전 학습 지식을 효과적으로 활용할 수 있도록 설계되어, 높은 fine-tuning 성능과 간편한 adaptation 능력을 유지하면서도 기존의 무거운 VLA 학습 방식과 동등하거나 그 이상의 성능을 달성합니다.
본 연구의 기여는 다음과 같이 요약할 수 있습니다.
- object-centric representation에 영감을 받아, 객체에 대한 시각 정보를 축약된 token 집합으로 압축하는 방식을 설계합니다.
- action 예측 시 정밀도를 보장하기 위해, agent와 관련된 visual patch를 식별하고 이를 object-centric token과 결합하는 간단한 접근 방식을 제안합니다.
- 전체 모델인 Oat-VLA는 modular하고 scalable한 구조를 가지며, 기존 VLA checkpoint를 재사용함으로써 효율적인 adaptation이 가능함을 보입니다. LIBERO benchmark에서 평가한 결과, action token accuracy와 task success rate 기준으로 수렴 속도가 2배 향상됨을 확인합니다.
- 마지막으로, real-world pick-and-place task에서 Oat-VLA를 실험한 결과, OpenVLA보다 더 높은 성공률을 보이며 보다 robust하게 동작함을 확인합니다.
Related Work
Vision-Language-Action Models
Vision-Language-Models의 generalization capability를 로봇 제어에 활용하기 위해, VLM을 robotics task에 fine-tuning하는 연구가 점점 증가하고 있습니다. RT-2는 frontier closed-sourced VLM을 visual task와 robotics task에 공동 fine-tuning하여 general-purpose robotics policy를 달성합니다. 동시에 OpenVLA 와 π0 는 유사한 방향의 open-source 노력을 대표합니다. 이들에 앞서, 대규모 robotics dataset으로 학습된 transformer architecture를 활용하여 general-purpose robotics policy를 달성하려는 여러 연구가 존재합니다. Gato 는language, vision, robotics task 전반에 걸쳐 학습된 최초의 transformer를 제시하였으며, RT-1 은 대규모 robotics dataset으로 학습된 대형 transformer architecture를 집중적으로 활용한 초기 연구입니다. Octo 와 JAT 는 downstream task에 대한 효율적인 fine-tuning을 목표로 설계된 open-source transformer policy를 제안합니다. 이와 더불어, spatial awareness, 3D information , 새로운 object에 대한 generalization recurrence 및 streaming capability, embodied chain-of-thought 등을 VLA에 통합하여 generalization을 향상시키려는 다양한 시도가 이루어지고 있습니다. 본 연구에서는 action prediction component를 개선하여 성능을 향상시킨 기존의 orthogonal한 연구와 달리, 계산 효율성 관점에서 VLA의 visual representation을 개선하는 데 초점을 둡니다.
Efficient VLMs, VLAs
VLA의 generalization capability를 향상시키는 연구와 동시에, 이러한 모델과 기반이 되는 VLM의 효율성을 개선하려는 연구도 다수 진행되고 있습니다. TokenLearner 는 token 수를 줄이기 위한 generic learned method를 제안하며, 다른 연구는 transformer의 attention layer 효율을 향상시킵니다. TinyVLA 는 더 작은 backbone과 diffusion-based action head를 사용하여 학습 및 inference 속도를 개선한 VLA를 제안합니다. 유사하게 MiniVLA 는 1B parameter model을 사용하여 성능이 우수한 VLA를 학습합니다. VLA-Cache 는 변화가 거의 없는 visual token을 적응적으로 식별하고, 이러한 “unchanged” token에 대해 계산을 재사용하는 caching mechanism을 제안하여 효율적인 처리를 가능하게 합니다. Deer-VLA 는 inference 단계에서 model size를 자동으로 조정하는 dynamic inference를 제안하여 성능 향상을 달성합니다. 이전 연구에서는 VLA tokenization 자체를 개선하는 방법을 다루었으나, 이는 action tokenization을 개선하는 방향으로, visual backbone을 개선하는 것을 목표로 하는 본 연구와는 orthogonal한 접근입니다.
Object-centric Representations for Robotics
Object-centric representation learning은 장면 내 개별 object를 모델링함으로 써 복잡한 환경에 대한 이해를 향상시키는 데 초점을 둡니다. Reinforcement learning을 넘어 robotics 및 imitation learning 분야에서도 활발하게 연구가 되고 있습니다. A3VLM은 object-centric 접근을 활용하여 robot-agnostic VLA를 학습하며, DexgraspVLA는 SAM을 활용하여 object-mask feature를 VLA에 추가 입력으로 제공합니다. 유사하게 Sam2Act는 SAM을 image encoder로 사용하여 multi-view policy를 학습하며, FOCUS는 SAM으로부터 mask supervision을 획득합니다. POCR 는 pre-trained robotic embedding을 위한 general object-centric framework를 제안합니다. 본 연구와 동시기에 ControlManip 은 pre-trained VLA를 object-centric representation에 conditioning하는 방식을 제안합니다. 본 연구에서는 object discovery를 위해 vision encoder를 적응시키는 unsupervised object-centric 접근을 사용하는 FT-Dinosaur를 활용합니다.
3 Method

VLA는 관측 $o$와 작업 설명 $\ell$이 주어졌을 때, 행동 $a$에 대한 분포 $p(a \mid o, \ell)$을 학습합니다. 본 연구에서는 $o \in \mathbb{R}^{C \times W \times H}$가 단일 카메라 이미지로 구성된다고 가정합니다. 관측은 DinoV2+SigLIP 과 같은 visual encoder $\mathrm{VisEnc}$를 사용하여 인코딩되며, 그 결과 visual token 집합 $v_{1 \ldots K} = \mathrm{VisEnc}(o)$를 얻습니다. 한편, language instruction은 기반 LLM의 tokenizer를 사용하여 인코딩되며, 이를 $l_{1 \ldots J}$로 표기합니다. 전체적으로 행동 분포는 다음과 같습니다:
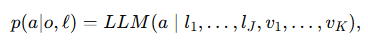
여기서 action에 대한 분포는 binning scheme을 사용하여 이산적으로 선택됩니다. 가장 일반적인 visual tokenization 전략의 관측을 patch로 분할한 뒤, visual encoder로 처리하고 이를 LLM에 입력하는 방식입니다. 예를 들어, $224 \times 224$ 픽셀 이미지는 $14 \times 14$ 픽셀 크기의 256개 patch로 분할될 수 있습니다. 이는 LLM이 $K = 256$개의 visual token을 처리하게 됨을 의미하며, 이는 일반적으로 언어 지시에 대해 처리되는 토큰 수보다 한 자릿수 더 많은 수입니다. 그 결과, visual token의 수는 VLA를 학습할 때 주요 병목 중 하나가 됩니다. 본 연구의 목적은 성능 손실 없이 visual token의 수 $K$를 크게 줄이는 것입니다.
3.1 Object-centric tokens
장면을 이해하기 위해서는 에이전트가 관측된 이미지의 모든 부분을 볼 수 있어야 합니다. embedded image patch를 VLA의 LLM에 입력하는 것은 안전한 설계 선택이지만, 정보 관점에서는 비효율적입니다. 이미지 내의 여러 patch는 종종 에이전트에게 irrelevant한 정보, 예를 들어 배경 정보를 포함합니다. 또한 이미지 내의 많은 patch는 동일한 entity를 표현할 수 있으며, 예를 들어 하나의 object가 여러 patch에 걸쳐 존재할 수 있습니다. 이러한 정보는 더 적은 수의 토큰으로 효율적으로 압축될 수 있으며, 이를 object-centric token이라고 부릅니다. semantic segmentation을 수행하는 object-centric model은 이미지 내 픽셀을 공통된 semantic 의미에 따라 그룹화를 진행할 수 있습니다.각 픽셀 그룹은 일반적으로 하나의 index를 할당되며, "object mask"로 참조될 수 있습니다. 관측 $o$가 주어졌을 때, 본 연구에서는 object extractor를 사용하여 이미지를 처리하고, $N$개의segmentation mask를 얻습니다. 즉, $m_{1 \ldots N} = ObjEnc(o)$이며, 여기서 $N$은 고정되거나 가변적인 수일 수 있습니다.
VLA를 위한 object-centric token을 얻기 위해, 본 연구에서는 다음의 연산을 수행합니다.
- Visual encoder를 사용하여 이미지의 모든 patch에 대한 visual token을 추출합니다.
- patch와 동일한 출력 해상도에서 object-centric model을 사용하여 object mask를 얻고, 해당 mask에 따라 visual token을 모읍니다.
- 동일한 obejct mask에 속한 token 정보를 압축하기 위해 pooling 연산을 수행합니다.
형식적으로 object-centric token을 다음과 같이 계산하게 됩니다:
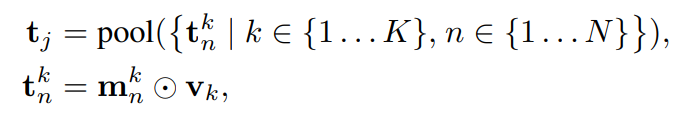
여기서 $m_k^n$은 patch 좌표 기준으로 $v_k$에 대응되는 object $n$의 mask입니다. 이 절차를 통해, 사용된 masking 전략에 따라 처리되는 visual token의 수를 1~2자릿수만큼 줄일 수 있습니다. 본 실험에서는 unsupervised object-centric model인 FT-Dinosaur를 채택합니다. FT-Dinosaur는 (i) 새로운 dataset에 대해 unsupervised 방식으로 유연하게 fine-tuning이 가능하고, (ii) 이미지에서 추출할 mask의 수를 고정할 수 있다는 두 가지 특징을 가지며, 이는 본 접근법에 적합합니다. Pooling 단계에서는 단순한 average pooling을 사용하며, 이에 대한 ablation은 Section 4.3에서 수행합니다. 주요 실험에서는 7개의 object mask만을 사용하며, 결과적으로 7개의 object-centric token을 얻습니다.
3.2 Agent-centric tokens
object-centric token은 무엇이 존재하고 어디에 있는지를 요약하지만, 본질적으로 high-frequency detail을 제거합니다. 정밀한 manipulation을 위해서는, 에이전트가 end effector와 object 간의 상호작용에 대한 정확한 정보를 보유하는 것이 중요합니다. object와 상호작용하는 동안, object와 end effector에 대한 정보가 서로 다른 object-centric token으로 집계될 수 있습니다. 그 결과, object를 접촉하는 것과 같은 상호작용 정보가 우연히 제거될 수 있습니다. 이러한 가능성을 방지하고, 항상 end effector에 대한 고해상도 정보를 에이전트에 제공하기 위해, 본 연구에서는 agent-centric token을 도입합니다. 단일 팔 로봇 manipulation 시스템에서, end effector는 일반적으로 로봇 팔에 부착된 gripper입니다. 카메라 관측에서 gripper를 식별하는 것은 에이전트의 action이 어디에서 실행되는지를 파악할 수 있게 합니다. 카메라 calibration이 존재하는 시스템에서는 gripper 위치를 로봇 pose로 부터 얻을 수 있습니다. 그러나 이러한 calibration은 종종 제공되지 않으며, 예를 들어 Open X-Embodiment dataset에서도 여러 dataset에서도 누락되어 있습니다. 일반적인 해법을 얻기 위해, 본 연구에서는 gripper detector model을 학습합니다. test time에 이 모델은 visual observation에서 gripper 위치를 나타내는 단일 2-D keypoint를 반환합니다.
VLA를 위한 agent-centric token을 얻기 위해, 다음의 연산을 수행합니다.
- (object-centric token과 공유되는 단계) visual encoder를 사용하여 이미지의 모든 patch에 대한 visual token을 추출합니다.
- gripper detector를 사용하여 카메라 관측에서 gripper 위치를 검출합니다.
- gripper 주변의 patch를 선택하여 에이전트 주변의 patch grid를 얻습니다.
이 절차는 에이전트의 end effector 위치 주변에서 임의의 수의 visual token을 선택할 수 있게 하며, 이를 통해 에이전트가 항상 자신의 action 결과를 확인할 수 있도록 합니다.
본 실험에서는 lightweight ResNet 기반 Faster R-CNN 구조를 사용하는 gripper detector를 채택합니다. gripper 학습은 Open X-Embodiment에서 수천 장의 수동 annotation된 프레임과, LIBERO dataset에서 자동으로 추출된 gripper 위치를 사용하여 supervised 방식으로 수행됩니다. agent-centric token으로는 $3 \times 3$ patch grid를 사용하며, 이는 총 9개의 agent-centric token을 생성합니다. 매우 드물게 gripper가 검출되지 않는 경우에는, agent-centric token이 전체 이미지의 모든 patch feature 값을 사용합니다.
3.3 Oat-VLA: Object-Action-centric Tokenization for VLAs
본 방법인 Oat-VLA는 object-centric token과 agent-centric token의 수를 줄임으로써, 보다 효율적인 VLA 학습 전략을 제공하는 것을 목표로 합니다. Oat-VLA에서 object-centric token은 장면에 대한 의미적으로 조작된 인지를 가능하게 하며, agent-centric token은 정밀한 manipulation을 가능하게 합니다. Oat-VLA의 visual tokenization 과정은 Figure 2에 도시되어 있습니다. visual tokenization은 본 접근법의 핵심적인 혁신 요소입니다. 이는 본 절에서 설명한 object-centric token 추출 과정과 agent-centric token 추출 과정으로 구성됩니다. 결과로 얻어진 token은 MLP projection을 거쳐 openvlal의 구조를 따르며 (Llama 2) LLM backbone에 입력됩니다. 중요한 점은, Oat-VLA는 LLM에 입력되는 token이 포함하는 정보를 파괴적으로 변경하지 않으며, 사전 학습된 visiual encoder로부터 얻어진 token을 단순히 aggregation 및 selection하는 연산만을 수행합니다. 따라서 section 4에서 보이듯이, 에이전트는 여전히 기본 VLM/VLA로부터 사전 학습된 지식을 활용할 수 있습니다.
$224 \times 224$ 이미지의 경우, Oat-VLA가 사용하는 visual token의 총 수는 16개입니다. 이는 7개의 object-centric token과 9개의 agent-centric token으로 구성됩니다. 동일한 이미지 해상도에서, 기존 OpenVLA의 visual backbone은 256개의 visual token을 추출합니다. 따라서 Oat-VLA는 visual token을 93.75% 적게 사용합니다 이러한 감소는 학습 중 batch size를 크게 증가시킬 수 있게 하며, Figure 1에서 관찰되듯이, OpenVLA 대비 약간 더 높은 성능을 달성하면서도 2배 이상 빠른 학습 속도(학습 step 수와 실제 시간 기준 모두)를 가능하게 합니다.
4 Experimental results
Figure 1에서는 Oat-VLA가 기존의 “original” 대응 모델인 OpenVLA보다 훨씬 빠르게 학습될 수 있음을 보입니다.
본 절의 목적은 다양한 학습 설정 전반에 걸쳐 Oat-VLA의 성능이 일관되게 OpenVLA와 동등하거나 이를 상회함을 상세히 입증하는 것입니다. 환경 측면에서는 두 가지 설정을 채택합니다. 하나는 네 개의 task suite를 포함하는 LIBERO 환경이며, 다른 하나는 UFACTORY xArm 6을 사용하여 테이블 위의 객체를 재배치하는 real-world 환경입니다. 아래의 OpenVLA 실험에서는, LIBERO dataset을 제외한 Open X-Embodiment dataset으로 사전 학습된 OpenVLA checkpoint에서 학습을 시작합니다. Oat-VLA 실험의 경우, Open X-Embodiment의 부분 집합에 대해 Oat-VLA architecture를 사용하여 200K step 동안 fine-tuning된 OpenVLA checkpoint에서 시작하며, 자세한 내용은 Appendix 7.2에 제시되어 있습니다. Prismatic VLMs나 PaliGemma와 같은 stock VLM checkpoint로부터 Oat-VLA를 학습하는 것은 향후 연구로 남깁니다.
4.1 Full Fine-tuning

본 절에서는 Oat-VLA가 새로운 dataset에서 VLA 모델의 모든 weight를 보다 효율적으로 fine-tuning할 수 있음을 보이고자 합니다. 이를 위해, 각 base VLA checkpoint에서 시작하여 Oat-VLA와 OpenVLA를 모두 전체 LIBERO dataset(SPATIAL, OBJECT, GOAL, 10, 90)에 대해 fine-tuning합니다. 다섯 개의 모든 subset에 대해 단일 action space normalization을 사용합니다. Oat-VLA에서 full fine-tuning은 batch size $8 \times 64 = 512$를 사용하여 수행되며, 8xH100 노드에서 평균적으로 초당 320개의 example을 처리함을 측정하였습니다. OpenVLA의 full fine-tuning은 batch size $8 \times 32 = 256$을 사용하여 수행되며, 동일한 8xH100 노드에서 평균적으로 초당 157개의 example을 처리합니다. Oat-VLA의 더 큰 batch size는, visual token 수 감소로 인해 sample당 GPU memory 요구량이 줄어들기 때문에 발생하는 본 방법의 고유한 이점입니다. 그 외의 모든 학습 설정은 OpenVLA와 동일하게 유지합니다.
모델은 네 개의 LIBERO task suite에서 평가됩니다. SPATIAL은 공간적 관계에 대한 에이전트의 이해를 평가하고, OBJECT는 object type에 대한 이해를 평가하며, GOAL은 task 지향적 행동에 대한 지식을 평가합니다. LONG, 또는 10으로도 불리는 suite는 다양한 object 상호작용과 다채로운 motor skill을 포함하는 장기 horizon task들로 구성됩니다. 각 task suite에 대해 100회의 evaluation을 수행합니다.
본 연구에서는 full fine-tuning을 사용하여 action token accuracy가 시간에 따라 어떻게 변화하는지를 분석하였으며, 이는 Figure 1에 제시되어 있습니다. 학습 중에는 5000 training step마다 checkpoint를 평가하여, 학습 효율 측면에서의 성능을 비교합니다. Figure 3에서는 training step에 따른 두 모델의 성능을 보고합니다. 전반적으로 Oat-VLA는 OpenVLA보다 약간 더 나은 성능을 보이며, 특히 도전적인 LIBERO 10 suite에서 더 큰 성능 우위를 보입니다. 중요하게도, Oat-VLA는 더 높은 batch size와 개선된 visual encoding 덕분에 2배 이상 빠르게 더 높은 success rate를 달성하며, 이는 덜 relevant한 정보를 제거하거나 압축함으로써 학습을 단순화하기 때문입니다.
4.2 LoRA Fine-tuning
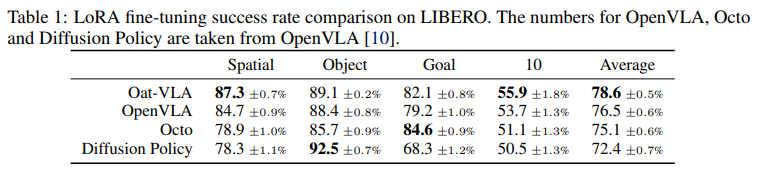
LoRA Fine-tuning 학습 효율성
- Oat-VLA가 OpenVLA보다 효율적입니다. 8xH100 노드 환경에서 Oat-VLA는 배치 크기 384, OpenVLA는 128로 설정되었으며, 초당 처리 속도도 Oat-VLA(384개)가 OpenVLA(197개)보다 빠릅니다. (OpenVLA는 LoRA 시 FSDP 비활성화로 배치 크기가 제한됨)
LIBERO 벤치마크 결과
- 성능 우위: Oat-VLA가 모든 태스크에서 OpenVLA보다 소폭 높은 성공률을 보였습니다.
- 학습 속도: Oat-VLA는 30K step 만에 우수한 성능에 도달한 반면, OpenVLA는 60K step이 필요했습니다.
- 한계: 두 모델 모두 정밀한 액션 예측이 필요한 Goal/Object 태스크에서는 Diffusion 기반 모델(Octo, Diffusion Policy)보다 성능이 낮았습니다.
Real-world 벤치마크 결과
- 평가 설정: xArm 6 로봇과 RGB 카메라를 사용하여 In-distribution와 Out-of-distribution를 모두 평가했습니다.
- 결과: Oat-VLA가 두 설정 모두에서 OpenVLA보다 일관되게 더 좋은 성능을 보였습니다.
- 정성적 평가: Oat-VLA가 물체를 집고 놓는 동작에서 더 정밀했습니다. 반면, OpenVLA는 허공을 집거나 엉뚱한 곳에 놓는 오류가 관찰되었습니다.
4.3 Ablations
Ablation study를 통해, visual token 내 정보를 압축하는 다양한 방식과 설계 선택의 타당성을 분석합니다. LIBERO benchmark에서 full fine-tuning 설정을 채택하고, 모든 모델을 20K training step 동안 학습합니다. 분석한 ablation은 다음과 같습니다.
- Single image token: attention pooling을 사용하여 모든 visual token의 정보를 하나의 token으로 압축합니다.
- Object-centric tokens only: Section 3.1에 설명된 방법을 사용하여 object token만을 추출하고, attention pooling으로 정보를 압축합니다.
- Oat-VLA(attention pooling): object-centric token과 agent- centric token을 모두 사용하며, object-centric pooling은 attention pooling layer를 사용합니다.
- Oat-VLA (average pooling): object-centric token과 agent-centric token을 모두 사용하며, object-centric pooling은 average pooling layer를 사용합니다(기본 설정).
결과는 Table 2에 제시되어 있습니다. 모든 visual token을 하나의 token으로 압축하는 것보다, object 별로 여러 token으로 정보를 압축하는 것이 특히 LIBERO Spatial에서 성능을 약간 향상시킴을 관찰하였습니다. Agent-centric token은 성능에 매우 큰 긍정적인 영향을 미치며, 성능 손실을 방지하는 데 있어 필수적입니다. 마지막으로, 추가적인 layer가 필요 없는 단순성 때문에, attention pooling보다 average pooling이 더 잘 작동함을 확인하였습니다. 다른 pooling 전략이 object token 정보를 더 효과적으로 압축할 가능성도 있으나, 이는 향후 연구로 남깁니다.
5 Discussion and conclusion
VLA를 대규모로 학습하는 것은 시각 및 언어 입력을 모두 처리하는 multimodal robotics system으로 나아가는 과정에서 매우 중요한 문제입니다. 그러나 VLA 학습은 막대한 계산 자원 요구와 긴 학습 시간이라는 여러 도전을 수반합니다. Oat-VLA에서는 object-centric token과 agent-centric token을 활용하여 visual tokenization 과정을 재구성함으로써, VLA의 학습 비용과 시간을 획기적으로 줄이는 방법을 제안합니다.
본 접근은 시스템의 암묵적인 inductive bias를 도입합니다. Agent-centric token의 경우, end-effector를 “에이전트가 세계와 상호작용하는 위치”에 대한 직관적인 proxy로 사용하였습니다. 이는 다수의 manipulator를 허용하고, 로봇의 다른 부분을 사용하는 non-prehensile manipulation까지 일반화되어야 합니다. Object-centric token의 경우, semantic segmentation을 수행하는 object-centric model을 사용합니다. 향후 연구에서는 데이터로부터 보다 자연스럽게 도출되는 object-agent-centric 유사 inductive bias를 탐색해야 합니다.
결론적으로, 본 연구가 VLA 및 다른 end-to-end 로봇 policy를 위한 효율적인 visual tokenization 분야의 추가 연구를 촉진하기를 기대합니다. 또한 본 연구가 더 많은 연구실이 foundational VLA 모델의 학습에 참여할 수 있도록 하는 계기가 되기를 바랍니다.
6 Limitations
본 연구에서는 단일 팔 로봇에서의 pick and place task에 대해서만 Oat-VLA를 평가하였습니다. Bi-manual setting이나 옷 개기와 같은 더 복잡한 task에서 Oat-VLA가 어떻게 동작하는지는 아직 밝혀지지 않았습니다. 본 연구에서의 prototype은 object-centric mask를 위한 FT-Dinosaur, gripper detector를 위한 Faster R-CNN, 그리고 VLA로서의 OpenVLA, 총 세 개의 서로 다른 모델로 구성되어 있습니다.모든 구성 요소가 동일한 visual backbone을 공유하도록 하는 것이 타당하며, 이는 success rate에는 변화를 주지 않으면서도 학습 시간을 약 5%에서 10% 정도 개선할 것으로 예상됩니다.
Appendix 7.7에서 보이듯이, A100 또는 RTX A5000 GPU를 사용할 경우, batch-of-1 inference speed에서는 Oat-VLA가 이점을 제공하지 못합니다.이는 inference time이 GPU RAM에서 GPU cache로 LLM weight를 로드하는 과정에 의해 지배되기 때문입니다.이러한 점은 다른 hardware architecture나, roll-out 중 병렬 inference로 인해 batch size가 증가하는 다른 action head를 사용하는 경우, 예를 들어 OpenVLA-OFT와 같은 경우에는 달라질 수 있습니다.