논문 주소: https://arxiv.org/pdf/2511.16449
Abstract
Vision-Language-Action모델은 embodied AI에서 큰 가능성을 보여주었지만, 연속적인 visual stream을 처리하는 데 따른 높은 계산 비용으로 인해 real-time 배포가 심각하게 제한됩니다. Token pruning은 salient한 visual token을 유지하고 중복된 token을 제거하는 방식으로, vision-Language Model를 가속화하기 위한 효과적인 접근법으로 부상하였으며, 효율적인 VLA를 위한 해결책을 제공합니다. 그러나 이러한 VLM 중심의 token pruning 방법들은 semantic salience metric (예: prefill attention)에만 기반하여 token을 선택하며, 고수준의 semantic 이해와 저수준의 action 실행으로 구성된 VLA의 고유한 dual-system 특성을 간과합니다. 그 결과 이러한 방법들은 semantic cue에 편향적으로 token을 유지하고, action 생성에 중요한 정보를 제거하며 VLA 성능을 크게 저하시킵니다.
이러한 간극을 해소하고자, 본 연구에서는 VLA 모델의 dual-system 특성과 로봇 manipulation에서의 temporal continuity를 활용하는, 범용적인 plug-and-play VLA 전용 token pruning 방법인 VLA-Pruner를 제안합니다. 구체적으로, VLA-Pruner는 visual token 유지에 대해 dual-level importance criterion을 채택합니다. 이는 semantic-level 관련성을 위한 vision-language prefill attention과 temporal smoothing을 통해 추정된 action-level 중요도를 반영하는 action decode attention으로 구성됩니다. 이 기준을 기반하여, VLA-pruner는 주어진 compute budget 하에서 semantic 이해와 action 실행 모두에 필요한 정보를 담는 compact하고 informative한 visual token 집합을 적응적으로 보존하는 새로운 dual-level selection 전략을 제안합니다. 실험 결과, VLA-Pruner는 다양한 VLA architecture와 여러 로봇 task 전반에 걸쳐 state-of-the-art 성능을 달성함을 보여줍니다.
1. Introduction
VLA 모델은 대규모 real-world 로봇 dataset을 활용함으로 써 VLA 모델은 시각적 장면을 인식하고 자연어 지시를 이해하며, 저수준 action을 직접 실행하여 다양한 시나리오에서 복잡한 task를 수행할 수 있었습니다. 그러나 real-time 배포 환경에서는 VLA 모델이 동적인 환경에서 연속적인 visual stream을 처리해야 하므로, 높은 계산 오버헤드로 인해 어려움을 겪고 있습니다. 이를 완화하기 위해 기존 연구들은 model lightweighting, quantization, early-exit와 같은 가속 기법을 VLA에 적용해왔습니다. 이러한 방법들은 일정 수준의 효과를 보이지만, architecture 수정이나 재학습을 요구하기 떄문에 일반화 측면에서 제약을 받습니다.
기존 연구에서는 vision-language model에서의 visual representaiton, 즉 visual token은 높은 중복성을 가지고 있습니다. 이에 따라, 가장 salient한 token만을 유지하고, 나머지를 제거하는 visual token pruning은 VLM inference의 효율성을 개선하기 위한 일반적이고 효과적인 접근법으로 자리잡았으며,VLA 가속을 위한 잠재적인 해법으로도 주목받고 있습니다. 이러한 방법들은 attention score, gradient 정보, feature diversity와 같은 중요도 기준을 정의하여 visual token의 중요성을 정량화하고, inference-time에 덜 중요한 token은 제거합니다. 시각적인 중복성을 줄임으로써, 이들은 image captioning, VQA, Video understanding과 같은 표준 VLM task에서 정확도 손실을 최소화하면서 상당한 계산 절감을 달성합니다.
최근의 진전에도 불구하고, 기존 token pruning 방법들은 주로 context prefilling 단계에서 측정되는 semantic salience metric에만 의존합니다. 예를 들어 FastV 에서는 prefill attention 분포를, SparseVLM에서는 text-to vision cross attention scroe를 사용하여 visual token을 순위화하고, 점수가 낮은 token을 제거합니다. 이러한 semantic-only 기준은 VLM에서는 효과적일 수 있으나, VLA 모델이 가지는 본질적인 dual-system 특성과는 정합되지 않습니다.
구체적으로 말하자면, VLA inference는 고수준의 semantic 이해과 task planning, 그리고 저수준 action 실행을 결합하며, vision-language prefill 단계와 action decode 단계 사이에는 서로 다른 시각적 요구가 존재합니다. 이에 따라 본 연구에서는 두 단계 간의 명확히 상이한 attention pattern을 관찰합니다. (Sec. 3.2 참조). 그 결과, 기존 방법들은 token 유지와 semantic cue 쪽으로 편향 시키는 경향이 있으며, action 생성에 중요한 세부 정보를 제공하여, 특히 높은 pruning ratio에서 VLA 성능을 크게 저하시킵니다 (Fig. 1 참조). 이는 선행 연구에서도 관찰된 바 있습니다. 따라서, 기존의 VLM 전용 token pruning 전략은 VLA 모델에 근본적으로 부적합하며, VLA 전용 방법의 필요성을 분명히 드러냅니다.
이러한 간극을 매꾸기 위해, 본 연구에서는 VLA 모델의 dual-system 특성에 부합하고 로봇의 manipulation 에서의 temporal continuity를 활용하는, 범용적인 plug-and-play vla token pruning 방법인 VLA-Pruner를 제안합니다 VLA-Pruner는 VLA token pruning을 위해 두 가지 핵심 통찰을 제공합니다. 첫째, VLA-Pruner는 visual token 유지를 위해 dual-level importance criterion을 채택합니다. 이는 semantic-level 관련성을 정량화하기 위한 vision-language prefill attention score와, action-level 중요도를 정량화하기 위한 action decode attention score로 구성됩니다. 이를 구현하는 데 있어 핵심적인 어려움은 decode attention이 prefill 단계에서는 이용 불가능하다는 점입니다. 그러나 본 연구에서는 로봇 manipulation의 temporal continuity로 인해, VLA의 action attention pattern이 시간에 따라 점진적으로 변화하며, 연속된 timestep 사이에서 상위 attention을 받는 visual patch가 상당 부분 중첩됨을 관찰합니다(Sec. 3.2 참조). 이러한 연속성을 활용하여,최근의 decode attention으로부터 통계적 temporal smoothing 기법(예: Exponential Moving Average)을 사용해 현재의 action-to-vision attention을 실용적으로 추정합니다.
둘째, VLA 성능을 보장하기 위해, 제안하는 dual-level token selection 전략은 중복성과 편향을 초래하는 취약한 attention score fusion을 피합니다. 대신, minimal-redundancy-maximal-relevance (mRMR) 원리에 기반하여 patch-wise scheme을 채택합니다. 구체적으로, semantic 수준 또는 action 수준 중 어느 하나에서라도 salient한 patch의 합집합을 먼저 취하여 관련성을 최대화한 뒤, 중복성을 줄이는 방식으로 이를 필터링하여, 주어진 compute budget을 만족하는 compact하면서도 informative한 visual token 집합을 생성합니다. 이러한 설계는 계산 오버헤드를 줄이는 동시에, semantic 이해와 action 실행 모두에 필수적인 정보를 적응적으로 보존합니다.
VLA-Pruner는 training-free 방식으로 동작하며, 대부분의 최신 VLA architecture에 대해 plug-and-play 가속 모듈로 활용될 수 있습니다. VLA-Pruner를 두 개의 시뮬레이션 환경(LIBERO , SIMPLER)과 세 가지 VLA 모델(OpenVLA, OpenVLA-OFT, π0)에서의 로봇 manipulation task에 대해 평가합니다. VLA-Pruner는 최대 1.8×의 speedup에 이르는 상당한 효율 향상을 제공하면서도, task success rate의 감소는 미미함을 보입니다. 87.5%의 pruning ratio에서도 VLA-Pruner는 합리적인 성능을 유지할 수 있습니다. 더 나아가, 정밀한 중복성 제거 덕분에, 50% pruning ratio에서는 모델 성능을 오히려 향상시킬 수 있음을 확인합니다. 마지막으로, 6-DoF xArm6 로봇에 실제로 배포하여 real-time 시나리오에서 실질적인 속도 향상을 달성함으로써, VLA-Pruner의 real-world 적용 가능성을 입증합니다.
2. Related Work
2.1. Vision-Language-Action Models (VLA)
대규모 Vision–Language Models는 시각적 인식과 언어적 추론을 결합함으로써 multimodal 학습을 크게 발전시켜 왔습니다. 이러한 발전을 바탕으로, Vision–Language–Action (VLA) 모델은 action modality를 도입하여 end-to-end motor control을 가능하게 합니다. 이들 모델은 일반적으로 대규모 VLM backbone을 채택하고, 로봇 데이터로 fine-tuning됩니다. Action 생성 방식은 OpenVLA와 같이 action을 language-like token으로 이산화하는 방식부터, π0와 같이 diffusion-policy head를 부착하는 방식까지 다양하며, 일반적으로 정밀한 상호작용을 위해 action-to-vision cross-attention에 의존합니다.
Object retrieval이나 assembly와 같은 로봇 manipulation task에서의 효과에도 불구하고, VLA 모델은 여전히 계산 비용이 매우 높아, 자원이 제한된 플랫폼에서의 real-time 배포를 저해합니다.
2.2. Visual Token Pruning for VLMs
Visual token pruning은 VLM에서 visual redundancy를 줄이기 위해 널리 사용되는 전략입니다. 한 가지 계열의 방법들은 semantic importance criterion을 정의하여 visual token의 순위를 매기고 제거합니다. 예를 들어 FastV는 초기 layer의 attention을 사용하고, SparseVLM은 text–to-vision cross-attention을 사용하며, DivPrune은 diversity 기반 선택을, HoloV는 crop-wise attention과 diversitry를 활용합니다. 다른 한 계열의 calibration 기반 접근 방법들(예: FitPrune, VTW)은 calibration set에서의 모델 출력을 분석하여 pruning layer나 ratio를 선택합니다. 그러나 첫 번째 계열은 주로 semantic salience에 의존하며 VLA의 action의존적 요구를 간과하여 성능 저하를 초래합니다. (Sec. 3.2 참조). 두 번째 계열은 offline calibration에 의존하므로 자원이 제한된 VLA 배포 환경에 부적합하며, 여전히 semantic salience에 기반합니다. 이러한 한계는 VLA 전용 pruning 방법의 필요성을 제기합니다.
2.3. Training-Free Acceleration for VLA Models
Vision token pruning은 최근 training-free VLA 가속 프레임워크에 통합되고 있습니다. 예를 들어 EfficientVLA, SP-VLA, SpecPruneVLA는 token pruning을 포함하는 구조적인 가속을 수행하고 있습니다. 그러나 이들 방법 역시 token 유지를 위해 semantic salience를 사용합니다. 그 결과, 성능과 속도의 균형을 맞추기 위해 추가적인 모듈(예: diffusion-feature cache, lightweight generation module, action-aware controller, layer reduction)에 의존하게 되며, 이는 일반성과 효과를 제한합니다. 최근의 VLA-Cache는 temporal continuity를 활용하여 정적인 visual token feature를 caching하는 방법을 제안하며, 유망한 방향을 제시합니다. 그러나 cache 기반 메커니즘은 직접적인 pruning보다 효율성이 낮고, 여전히 task-relevant token을 보존하기 위해 text-to-vision cross-attention에 의존하는 coarse-grained 방식입니다. 이러한 한계들은 VLA 모델의 dual-system 특성을 간과한 데서 기인합니다(Sec. 3.2 참조). 본 논문에서는 token pruning이 성능 손실 없이도 VLA를 크게 가속할 수 있음을 보입니다.
3. Preliminary Analysis
3.1. Background
VLA Inference.
Vision-Language-Action (VLA) 모델은 시간 단계 $t$에 걸쳐 ${V_t, L_t}$ 형태의 순차 입력을 처리하여 $A_t$를 생성합니다. 여기서 $V_t$는 입력 visual observation을 나타내고, $L_t$는 language task instruction을 나타내며, $A_t={a^t_1,\ldots,a^t_{\hat N}}$는 예측된 action token을 의미하고, 이는 실행 가능한 로봇 action으로 detokenize될 수 있습니다. 텍스트 입력은 $N$개의 text token $E^t_\tau={\tau^t_1,\ldots,\tau^t_N}$으로 tokenize됩니다. Vision encoder는 $V_t$를 image feature로 처리한 뒤, projector를 사용하여 $M$개의 visual token $E^t_v={v_1,\ldots,v_M}$으로 투영합니다. 이들 token은 로봇 상태를 나타내는 proprioceptive token과 함께 Transformer 입력을 구성합니다. Self-attention은 token 수에 대해 이차적으로 스케일링되므로, $M$개의 visual token(일반적으로 $M \gg N$)이 inference 비용을 지배합니다.
VLA Attention Breakdown.
VLM과 마찬가지로, VLA 모델은 token 간 상호작용을 위해 transformer의 attention 메커니즘에 의존합니다. 일반성을 잃지 않고, 아래에서는 single-head attention을 설명합니다. 각 layer $l$에서, 모델은 visual token의 이전 layer hidden state $H^{l-1}v \in \mathbb{R}^{M \times d}$와 textual token의 이전 layer hidden state $H^{l-1}\tau \in \mathbb{R}^{N \times d}$를 입력으로 받습니다. 수학적 단순화를 위해 시간 및 layer에 대한 superscript는 생략하고, proprioceptive token은 vision-language context의 일부로 취급합니다. 이 입력들은 선형 projection을 통해 query $Q$, key $K$, value $V$로 변환됩니다. 그 다음, attention 및 상호작용을 위한 공유된 vision-language context는 $K^{vl} \in \mathbb{R}^{(N+M)\times d_k}$, $V^{vl} \in \mathbb{R}^{(N+M)\times d_v}$로 구성됩니다. 본 연구에서는 VLA inference 방법을 두 단계로 나눕니다:
(1) Vision-Language prefill Stage.
이 단계에서는 query가 text token과 vision token에서 생성되며, $Q^{vl} \in \mathbb{R}^{(N+M)\times d_k}$입니다. Attention matrix는 다음과 같이 계산됩니다.

각 input visual patch에 대한 attention score는 다음과 같이 계산됩니다.
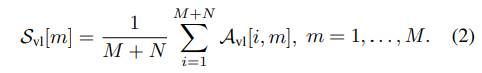
(2) Action decode Stage.
이 단계에서는 query가 action token에서 생성되며, $Q^{act} \in \mathbb{R}^{K \times d_k}$입니다($K=1$은 autoregressive, $K=\hat N$은 chunk-based 를 의미합니다). Attention은 다음과 같이 계산됩니다.

Autoregressive의 경우, $\hat N$개의 decoding step에서의 attention vector가 연결되어 최종 attention matrix를 구성합니다.
이 단계에서의 action-to-vision attention score는 다음과 같습니다.
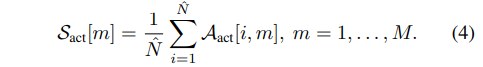
$S^{vl}$과 $S^{act}$는 각각 semantic 이해와 action 실행에 대해 각 patch의 중요도를 정량화합니다.
3.2. Motivating Observation for VLA-Pruner

본 연구에서는 VLA inference의 고유한 특성을 체계적으로 분석합니다 (Fig. 2). 그 결과, 기존 VLM 전용 token pruning 방법이 VLA 모델에 적용될 때 가지는 근본적인 한계를 식별하였으며, 이는 VLA-Pruner를 제안하게 된 동기를 제공합니다.
Motivation 1: Visual token prefilling dominates computational overhead for VLA models.
이전 연구에서도 지적되었듯이, Visual token의 도입은 LLM에 비해 상당한 메모리 및 계산 오버헤드를 불가피하게 초래합니다. VLA 모델의 경우, 처리되는 visual token의 수는 프레임당 일반적으로 $256 \times n$개($n$은 camera view 수)로, text token(약 30–50개)과 action token(약 7–56개)보다 한 자릿수(order of magnitude) 더 많습니다. 따라서 입력 visual stream의 prefilling이 계산 비용의 주요 원인이 됩니다. Visual representation은 높은 중복성을 가지므로, visual token pruning은 VLA 가속을 위한 큰 가능성을 보입니다.
Motivation 2: Visual token pruning must account for the dual-system nature of VLA models.

VLA 모델의 효율성은 고수준의 semantic 이해 및 task planning과 저수준 action 실행을 통합하는 본질적인 dual-system 능력에서 비롯됩니다. 본 연구의 핵심 통찰은 이러한 내재적 이중성이 VLA inference 과정에서 직접적으로 나타나며, vision-language prefill 단계와 action decode 단계 사이에 상이한 시각적 요구를 유발한다는 점입니다. 이를 검증하기 위해 본 연구에서는 LIBER benchmark에서 OpenVLA와 attention 분포를 분석했습니다.
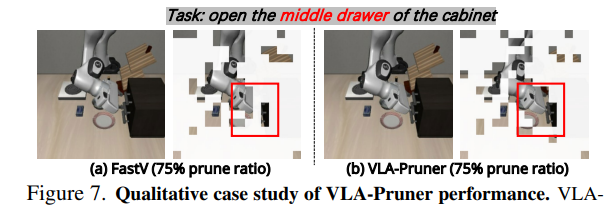
그 결과, VLA inference는 뚜렷이 다른 attention pattern을 보이며, prefill attention은 넓고 semantic한 분포를 보이는 반면, action decode attention은 Fig. 2c와 Fig. 2d에서 예시되듯 정밀한 motor control에 필수적인 국소적 집중을 보입니다. 정량적으로, vision-language prefilling과 action decoding 간 상위 attention visual token의 overlap ratio는 평균적으로 약 50%이며, 종종 30%이하로 떨어지기도 합니다.(Fig 2). Attention scroe는 모든 Trasnformer layer를 걸쳐 평균화됩니다. 기존 pruning 전략은 이러한 중요한 attention 분기를 간과하여, 특히 높은 압축 비율에서 prefilling 단계에서는 덜 salient하지만 action 생성에는 중요한 token을 조기에 제거할 위험이 있습니다. 이는 소수의 high-attention token만 제거해도 성능이 크게 저하된다는 점에서 매우 치명적입니다. Fig. 7에서 이에 대한 정성적 예시도 제공합니다.
Motivation 3: VLA token pruning should exploit temporal continuity in robotic manipulation.
Visual token prefilling이 계산 오버헤드를 지배하므로(Motivation 1), token pruning은 early-layer prefilling 단계에서 수행되어야 합니다. 그러나 이상적인 전략은 semantic 수준과 action 수준의 token 중요도를 모두 고려해야 하는 반면(Motivation 2), action decode attention score(action 수준 중요도의 실용적 proxy)는 prefilling 시점에는 이용할 수 없습니다. 다행히도, VLA 로봇 manipulation은 temporal continuity를 보입니다 action-to-vision attention map이 강한 단기 시간적 상관관계를 가지며, 시점 $t$와 $t-1$에서 action decoding 중 상위 attention을 받는 visual token이 지속적으로 높은 overlap ratio를 보임을 관찰합니다(Fig. 2는 LIBERO task 전반에 대한 평균과 대표적인 rollout을 제시합니다). 이러한 temporal continuity는 통계적 temporal smoothing 기법을 현재의 action-to-vision attention을 추정하기 위한 실용적이고 효과적인 proxy로 만들어 줍니다.
4. Methodology
4.1. Problem Formulation
본 연구에서는 token pruning 문제를 다음과 같이 정의합니다. Visual token 집합 $E_v$가 주어지고 $|E_v|=M$이며, 목표 subset 크기가 $\tilde M < M$일 때, 목표는 VLA inference에 중요 정보를 보존하는 subset $\tilde E_v$를 선택하는 것입니다.
형식적으로, 우리는 index subset $I \subseteq {1,\ldots,M}$ 중 $|I|=\tilde M$을 선택하는 매핑 함수 $f$를 정의하고, 유지되는 visual token을

로 구성합니다. 목표는 pruning 전후의 모델 출력 차이를 최소화하는 매핑 함수 $f$를 찾는 것입니다.

여기서 $P=P(A\mid E_\tau,E_v)$이고 $\tilde P=P(A\mid E_\tau,f(E_v))$입니다. $P(\cdot\mid\cdot)$는 VLA 모델의 조건부 생성 확률을 의미합니다. $\mathcal{L}$은 pruning 유무에 따른 모델 출력 차이를 측정하는 loss 함수이며, $\tilde M$은 유지되는 token 수를 나타냅니다. 개념적으로 $P$를 vision-language prefill $P_{vl}$과 action decode $P_{act}$로 분해합니다.
$Z_\tau, Z_v$를 prefilling 이후의 textual token과 visual token의 모든 hidden representation이라고 하면, 비형식적으로
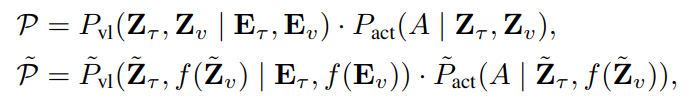
로 표현할 수 있습니다.
여기서 $f$는 hidden visual representation $\tilde Z_v$에서도 동일한 index를 제거합니다. Motivation 2에서 언급했듯이, semantic 수준 $\mathcal{L}(P_{vl},\tilde P_{vl})$ 또는 action 수준 $\mathcal{L}(P_{act},\tilde P_{act})$ 중 하나만을 사용하는 single-level objective로 $f$를 최적화하면 suboptimal한 pruning으로 이어집니다. 이를 해결하기 위해 VLA-Pruner를 제안합니다.
4.2. The Proposed VLA-Pruner
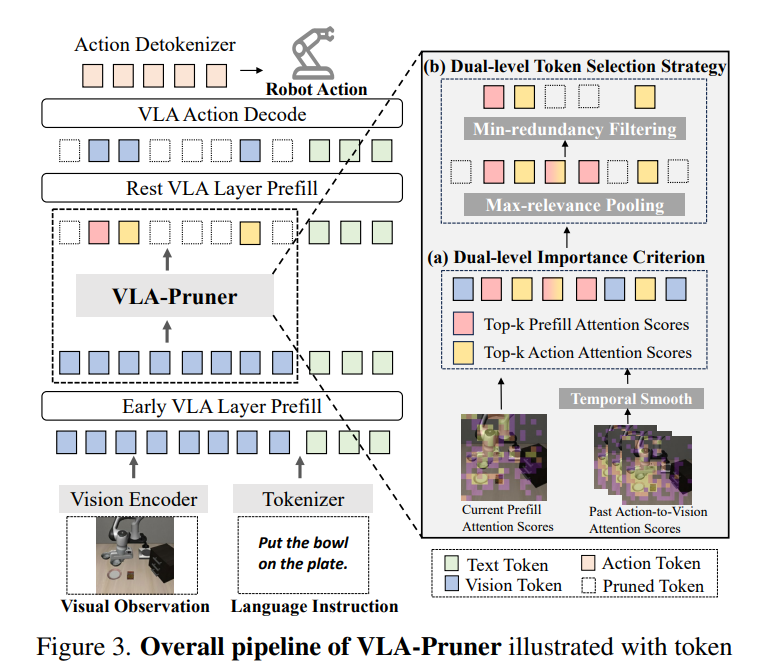
VLA-Pruner는 (a) semantic 수준과 action 수준의 중요도를 모두 포함하는 dual-level token importance criterion을 채택하고, 이에 대응하여 (b) dual-level relevance와 redundancy를 적응적으로 처리하는 dual-level token selection strategy를 제안합니다. 전체 파이프라인은 Fig. 3에 도시되어 있습니다.
(a) Dual-level Token Importance Criterion
VLM의 경우, 기존 연구는 prefill 또는 text-to-vision attention score가 vision token의 중요도를 효과적으로 정량화할 수 있음을 보여주었습니다. VLA의 경우, 앞서 논의한 바와 같이(Sec. 3.2), semantic 수준과 action 수준의 visual 요구가 모두 충족되어야 합니다. 이를 위해 VLA-Pruner는 다음의 dual-level token importance criterion을 채택합니다.
(1) semantic 수준 관련성을 정량화하기 위한 prefill attention score $S^{t}{vl}$(Eq. 2)와,
(2) action 수준 중요도를 정량화하기 위한 action decode attention score $S^{t}{act}$(Eq. 3)입니다.
Motivation 3에서 논의했듯이, 우리는 VLA manipulation의 temporal continuity를 활용하여 image patch에 대한 현재 action attention score $S^{t}{act}$를 추정합니다. 이는 과거 추세 ${S^{t-1}{act},S^{t-2}{act},\ldots}$로부터 $S^{t}{act}$를 예측하는 time-series forecasting 문제로 정식화됩니다. Classical한 training-free forecasting 방법으로는 averaging, autoregressive model, exponential smoothing 등이 있습니다. 이 중 Exponential Moving Average (EMA)는 최근 관측치를 강조하고 과거 관측치를 감쇠함으로써 noise를 줄이고 temporal trend를 포착하는 간단하면서도 효과적인 방법으로, 금융, 경제, 기상, 로봇 manipulation 등 다양한 분야에서 활용되어 왔습니다. 이를 직접 적용하면 다음과 같습니다.

여기서 $\alpha\in[0,1]$는 smoothing factor이고, $\hat S^{t-1}{act}$는 이전 timestep에서의 smoothed prediction, $S^{t-1}{act}$는 해당 관측 결과입니다.
Decaying Window Average Mechanism.
VLA manipulation에서는 단기 문맥이 더 중요하므로, 보다 단순하고 직관적인 decaying window average 메커니즘을 제안합니다. 이 방법은 최근 $w$개의 timestep을 고려하고 명시적인 지수 감쇠를 적용합니다. 형식적으로, 이전 $w$ step의 action attention score ${S^{t-1}{act},\ldots,S^{t-w}{act}}$를 smoothing하여, 현재 step의 추정 score $\hat S^{t}_{act}$를 다음과 같이 계산합니다.
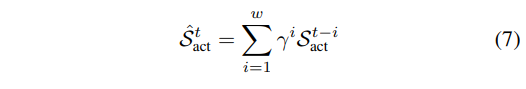
여기서 $w$는 window size를 정의하고, $\gamma\in[0,1]$는 decay rate를 제어합니다. 이 formulation은 현재 action attention score를 추정하기 위한 간단하면서도 효과적인 메커니즘을 제공합니다. 이후 논의에서는 간결성을 위해 시간 superscript $t$를 생략합니다
Remark 1.
Temporal smoothing 방법은 action attention의 동적 추세를 안정적으로 추정할 수 있지만, target switching과 같은 급격한 변화에서는 실패할 수 있습니다. 예를 들어, LIBERO-Long task “put both the alphabet soup and the tomato sauce in the basket”에서는 soup을 놓는 동안의 action attention이 tomato sauce에 잘 대응되지 않습니다. 가능한 해결책으로는 attention shift를 예측하는 lightweight predictor나, 예측–관측 간 큰 불일치가 발생할 경우 pruning을 우회하는 메커니즘이 있습니다. 그러나 일반성과 유연성을 보장하기 위해, 이러한 근본적인 문제를 dual-level token selection strategy를 통해 해결합니다.
(b) Dual-Level Token Selection Strategy.
Dual-level token importance criterion에 기반하여 token을 유지하는 직관적인 접근법은 semantic attention score $S_{vl}$과 action attention score $\hat S_{act}$를 정규화한 뒤, 가중합을 취하고, 가중 점수 기준 상위 $\tilde M$개의 token을 선택하는 것입니다. 그러나 이 방식은 근본적인 한계를 가집니다. 첫째, 민감한 가중치 hyperparameter를 도입하여 신중한 튜닝이 필요하며, 이는 robustness와 generalizability를 저해합니다. 둘째, 단계 내 및 단계 간 redundancy를 무시합니다. 기존 연구에서 지적되었듯이, attention 기반 pruning은 유사한 token을 유지하는 경향이 있습니다. 또한 score-level fusion은 prefilling과 decoding 모두에서 salient해 보이지만 어느 단계에도 필수적이지 않은 token을 유지하는 경향이 있습니다. 예를 들어, 로봇 팔에서 중간 관절은 두 단계 모두에서 salient하게 보일 수 있으나, 실제 실행에 중요한 end-effector는 과소평가될 수 있습니다. 마지막으로, action attention 추정치 $\hat S_{act}$가 항상 신뢰 가능하다고 암묵적으로 가정하는데, 이는 급격한 attention 변화 상황에서는 성립하지 않을 수 있습니다(Remark 1 참조).
Patch-wise Combine-then-Filter.
이러한 한계를 피하기 위해, feature selection을 위한 정보이론적 패러다임인 minimal-Redundancy-Maximal-Relevance (mRMR) 원리를 차용합니다. mRMR은 관련성을 최대화하면서 redundancy를 최소화하는 것을 제안합니다. 이에 영감을 받아, dual-level token selection strategy는 patch-wise combine-then-filter 메커니즘을 따르며, 절차를 세 단계로 구성합니다.
(1) Dual-level Top-k Selection.
먼저 dual-level top-k selection을 통해 두 개의 후보 token subset을 구성합니다.

여기서 $\tilde M$은 목표 token budget입니다. 이 단계는 고수준 semantic 이해를 위한 salient token 집합 $C_{vl}$과 저수준 action 실행을 위한 $C_{act}$를 각각 식별합니다.
(2) Relevance-Maximization Pooling.
다음으로 두 subset을 결합하여 후보 pool을 형성합니다.
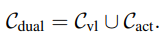
이 subset $C_{dual}$은 두 단계의 정보 요구를 모두 충족하는 token을 포함하며, task relevance를 최대화합니다.
Attention divergence로 인해(Motivation 2), 일반적으로 $|C_{dual}|>\tilde M$입니다.
(3) Redundancy-Minimization Filtering.
이 단계는 후보 $C_{dual}$ 내에서 redundancy를 줄여 목표 budget $\tilde M$을 만족시키는 것을 목표로 합니다. 이를 위해 우리는 최종 선택된 subset의 diversity를 최대화합니다. 선행 연구를 따라,이를 후보 pool $C_{dual}$ 내에서의 Max–Min Diversity Problem (MMDP) 로 정식화합니다.여기서 목표는 크기가 $\tilde M$인 subset $C \subset C_{dual}$을 찾아, 그 원소들 간의 최소 pairwise distance를 최대화하는 것입니다.

여기서 $C$는 $C_{dual}$의 임의의 $\tilde M$개 원소로 이루어진 subset이며, $v_i, v_j \in E_v$는 $C$에 포함된 임의의 $i,j$에 대응하는 입력 image patch embedding입니다. 거리 함수 $d(\cdot,\cdot)$는 cosine distance로 정의됩니다.
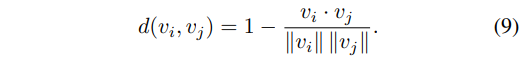
MMDP 문제의 해는 $C_{dual}$ 내에서 요소 간 redundancy를 최소화하는 subset입니다. MMDP는 여러 exact 방법 및 heuristic 방법으로 해결할 수 있습니다. 효율성을 위해, 현재 유지된 집합과의 최소 거리가 최대가 되도록 token을 반복적으로 추가하는 greedy 알고리즘을 사용하여, $\tilde M$개의 token에 도달할 때까지 진행합니다.Local optimum을 벗어나기 위해, 첫 번째 token은 second-nearest distance가 최대인 token으로 초기화합니다.Step (3)과 전체 token selection 방법은 Algorithm 1과 Algorithm 2에 상세히 기술되어 있으며(Appendix A 참조), 해당 절차를 통해 최종 token subset이 결정됩니다.
Remark 2.
본 방법은 mRMR objective에 대한 heuristic 해법입니다. 앞선 두 단계는 task relevance를 최대화하며, 마지막 단계는 feature redundancy를 최소화합니다. Remark 1에서 언급한 문제는 prefill attention을 통해 급격한 attention shift를 grounding하고, diversity maximization을 통해 이를 유지함으로써 해결됩니다.
Remark 3.
Step (3)은 diversity 기반 pruning을 통해 redundancy를 줄이는 DivPrune [2]와 유사한 측면을 가집니다. 그러나 DivPrune은 relevance maximization 단계를 포함하지 않기 때문에 핵심 token을 식별하지 못합니다. Max-relevance와 Min-redundancy를 결합함으로써, VLA inference에서 요구되는 dual-level 정보 특성에 더 잘 부합하는, 다양성과 중요성을 모두 갖춘 token subset을 유지합니다.
(c) Implementation Details.
VLA-Pruner는 VLA 모델 내 Transformer layer $K$에서 visual token을 pruning하며, $K$는 3으로 설정합니다. Token 선택은 마지막 layer의 prefill attention과, 과거 timestep에서의 action-to-vision attention을 후반부 layer에 대해 평균화한 뒤 temporal smoothing을 적용하여 수행합니다(노이즈 감소 목적). Pruned token은 이후의 모든 prefill layer에서 제거됩니다.
FlashAttention에 적응하기 위해, SparseVLM [60]에서 제안된 adaptation 기법을 적용할 수 있습니다. Decaying window average의 경우, window size $w$와 decay rate $\gamma$는 경험적으로 각각 3과 0.8로 설정합니다. 충분한 action attention history를 기록하기 위해, VLA-Pruner는 $w$ step 동안 warm-start됩니다. VLA-Pruner는 action-to-vision cross-attention을 사용하는 VLA architecture에 대해 plug-and-play 가속 모듈로 동작하며, 이는 최신 VLA 모델에서 공통적으로 사용되는 메커니즘입니다. 구체적으로, (i) autoregressive policy (예: OpenVLA ), (ii) action-chunk decoder(OpenVLA-OFT [24]), (iii) π0 [4]와 같은 diffusion-head policy를 지원하며, 이 경우 flow-matching step 전반에 걸쳐 action attention score를 평균화합니다. 계산 복잡도에 대한 분석은 Appendix A.2에 제시되어 있습니다.
5. Experiments
VLA-Pruner를 simulation 환경과 real-world 환경 모두에서 평가합니다.Simulation 환경에서는 open-source VLA 모델인 OpenVLA, OpenVLA=OFT, π0를 대상으로 LIBERO benchmark 와 Simpler enviroment를 사용하여 VLA-Pruner를 평가합니다. 모든 실험은 NVIDIA RTX 4090 GPU에서 수행됩니다.
5.1. Experimental Setup
Baselines
본 연구에서는 주어진 compute budget 하에서 VLA-Pruner를 다양한 training-free 가속 방법들과 비교합니다. Baseline에서는 state-of-the-art token pruning 방법인 FastV, SparseVLM, DivPrun와 VLA 전용 방법인 VLA-Cache가 포함됩니다. Baseline과 VLA 모델에 대한 자세한 설명은 Appendix B.1에 제시되어 있습니다. EfficientVLA는 기존 연구와 유사한 token pruning 전략(attention과 diversity 사용)을 채택하므로, 해당 결과와 추가적인 token pruning baseline은 Appendix B.3에 포함합니다.
Evaluation Protocol.
모든 방법은 동일한 pruning budget 하에서 평가됩니다. 포괄적인 비교를 위해, 50%, 75%, 87.5%의 다양한 pruning ratio를 포함합니다. 평가 지표는 주로 task success rate(%), inference latency(ms), FLOPs(T)를 포함합니다.
5.2. Evaluation Benchmarks
본 절에서는 평가 benchmark를 소개하며, 추가적인 세부 사항은 Appendix B.2에 제시되어 있습니다.
LIBERO.
LIBERO benchmark는 manipulation generalization의 상보적인 측면을 평가하는 네 개의 suite(Spatial, Object, Goal, Long)로 구성됩니다. 각 suite는 10개의 서로 다른 task를 포함하며, task당 50개의 evaluation episode(즉, suite당 총 500 episode)로 구성됩니다. OpenVLA와 OpenVLA-OFT를 따르며, 표준 evaluation 설정(OpenVLA-OFT의 경우 action chunk를 8로 설정)과 공식 weight를 사용하여 비교 가능성을 보장합니다.Architecture 간 일반화를 검증하기 위해, diffusion-head 기반 모델인 π0의 결과도 포함합니다(Appendix B.4 참조).
SIMPLER.
SIMPLER simulator 는 sim-to-real gap을 줄이기 위한 두 가지 상보적인 설정을 제공합니다.이는 visual matching(VM)과 variant aggregation(VA)입니다 세 가지 task와 해당 설정에 대한 평가 결과를 보고합니다.구체적으로 Move Near, Pick Coke Can(VA 설정), Open/Close Drawer(VM 설정)입니다. 이들 task–setting 쌍은 vanilla OpenVLA가 비자명한 success rate를 달성하는 경우로 선택하여, 합리적인 비교가 가능하도록 합니다.
Real Robot Evaluation.
Real-world 환경에서의 VLA-Pruner 성능을 평가하기 위해, parallel gripper를 장착한 6-DoF xArm6 로봇 팔을 사용하여 실험을 수행합니다. 본 연구에선는 서로 다른 object를 포함하는 네 가지 manipulation task를 실행하며, 각 task마다 100회의 trial을 수행합니다.
(1) Can Stack: 캔을 집어 박스 위에 쌓기입니다.
(2) Cup Pour: 컵을 들어 컵 안의 작은 공을 박스에 붓기입니다.
(3) Cube Place: 큐브를 집어 박스 안에 놓기입니다.
(4) Bottle Place: 병을 집어 박스 안에 놓기입니다.
5.3. Main Results
Results on LIBERO.
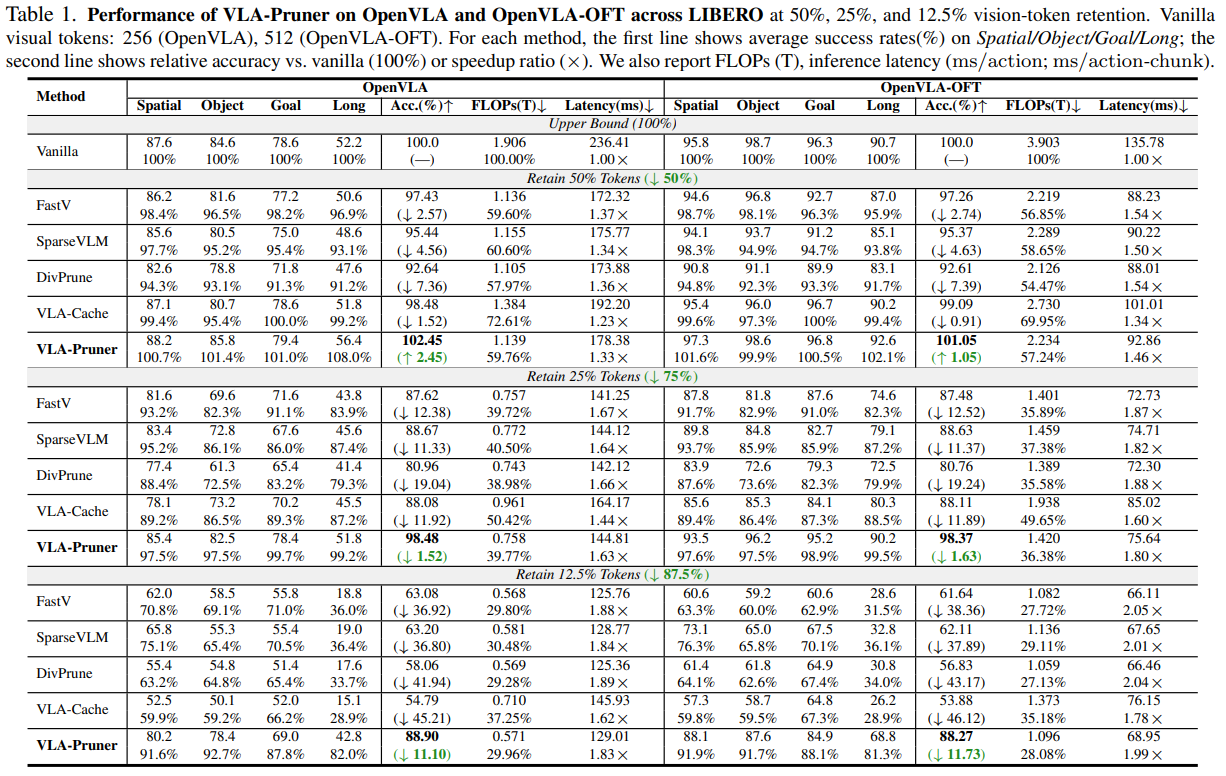

본 연구에서는 LIBERO benchmark에서 fine-tuned OpenVLA와 OpenVLA-OFT를 대상으로 VLA-Pruner를 평가합니다. Table 1은 token retention ratio가 50%, 25%, 12.5%일 때 네 개 suite에 대한 success rate를 보고합니다. VLA-Pruner는 모든 설정에서 training-free 가속 방법 중 가장 높은 success rate와 relative accuracy를 달성합니다. 12.5% retention ratio에서도 OpenVLA와 OpenVLA-OFT에서 각각 88.9%, 88.27%의 relative accuracy를 유지하며, baseline 대비 최대 34.39%까지 우수한 성능을 보입니다. 50% retention ratio에서는 정밀한 noise filtering으로 policy 실행이 안정화되어 success rate가 오히려 향상되며, 이는 LIBERO-Long에서 4.2%의 success rate 개선으로 확인됩니다. DivPrune은 VLM inference에는 유리하지만, 로봇 manipulation에는 보다 국소적인 visual detail이 필요하므로 VLA 성능을 저하시킵니다. VLA-Cache는 temporal awareness로 인해 경쟁력 있는 결과를 보이나, text-to-vision attention 기반의 coarse-grained 선택 전략으로 인해 높은 compression ratio에서는 실패합니다. Fig. 4는 pruning ratio 변화에 따른 VLA-Pruner 성능을 시각적으로 제시합니다. π0에 대한 결과는 Appendix B.4에 제시되어 있습니다.
Results on SIMPLER.

SIMPLER environment에서 cross-environment generalization을 평가합니다. Table 2는 75% compression ratio에서 OpenVLA를 대상으로 VLA-Pruner와 가속 baseline을 비교합니다. VLA-Pruner는 accuracy를 가장 잘 보존하며, 환경 간 전이에 대해 강건함을 보입니다.
Results on Real Robot.
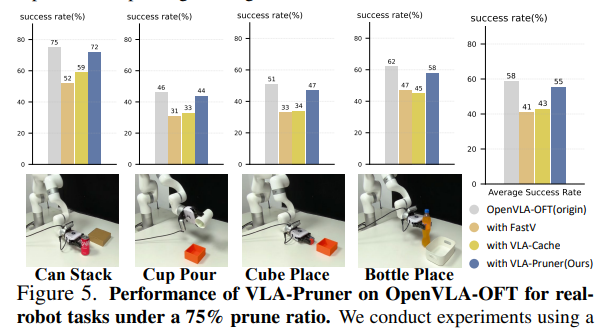
OpenVLA-OFT로 제어되는 실제 6-DoF xArm6 로봇 팔에서 real-world 성능을 평가합니다. Fig. 5는 75% token pruning ratio에서의 결과를 보고합니다. VLA-Pruner는 가장 높은 relative accuracy를 달성하며, 실제 로봇 배포에서의 실용성을 입증합니다.
Efficiency Analysis.
Table 1에는 inference latency(ms/action 또는 ms/action-chunk)와 FLOPs(T)를 포함한 inference 효율 지표를 보고합니다. 동일한 pruning ratio에서 VLA-Pruner는 다른 visual token pruning 방법과 유사한 speedup을 달성합니다. Redundancy filtering에서의 거리 계산으로 인해 FastV보다 latency가 약 5 ms 높지만, 성능은 현저히 우수합니다. 25% retention ratio에서는 VLA-Pruner가 50% retention의 token pruning baseline보다 더 나은 성능을 보이면서도, 약 16% 더 빠르고 약 20% 적은 FLOPs를 사용합니다. VLA-Pruner는 VLA-Cache보다 더 빠르고 compute 효율적입니다. 과거 attention을 저장해야 하지만, Max GPU memory 증가는 무시할 수 있는 수준입니다(Appendix B.5.1 참조).
5.4. More Results
Ablation Studies.

본 연구에서는 (a) dual-level importance criterion과 (b) patch-wise dual-level token selection strategy를 검증하기 위해 세 가지 변형을 비교합니다.
(1) prefill-only는 prefill attention으로 token을 선택합니다.
(2) action-only는 action attention으로 token을 선택합니다.
(3) score-fusion은 carefully fine-tuned weight를 사용하여 prefill과 action attention의 가중합으로 token을 순위화합니다.
Fig. 6에서 보이듯이, prefill-only는 고수준 semantic은 유지하지만 저수준 제어를 저해하고, action-only는 단기 제어는 개선하지만 semantic grounding과 task planning을 희생하여, 어느 쪽도 VLA 성능을 충분히 유지하지 못합니다. Score-fusion은 prefill-only보다도 성능이 낮습니다. 또한 Fig. 6에서는 temporal decay window size $w$에 대한 ablation을 수행하여, 본 방법의 강건성과 VLA manipulation의 단기 temporal continuity를 확인합니다. $w=1$인 경우 마지막 timestep의 action attention만을 사용하게 되며, 이는 성능 저하로 이어집니다. Decay rate $\gamma$와 pruning layer $K$에 대한 추가적인 ablation은 Appendix B.5.2에 제시되어 있습니다.
Qualitative Visualization.
Fig. 7에서는 VLA-Pruner의 정성적 사례 연구를 제시합니다. VLA-Pruner는 정밀한 action 실행을 위한 핵심적인 국소 visual 정보를 보존하면서도, 광범위한 semantic 이해를 유지합니다.
6. Conclusion
본 연구에서는 효율적인 VLA inference를 위한 training-free token pruning 방법인 VLA-Pruner를 제안합니다. VLA 모델이 가지는 고수준의 semantic 이해와 저수준 action 실행이라는 dual-system 특성을 부합하도록, VLA-pruner는 semantic 수준 관ㄹ녀성과 action 수준 중요도를 통합한 dual-leve token importance criterion을 사용합니다. 이 기준을 기반하여 제안한 dual-level token selection strategy는 visual token을 적응적으로 유지합니다. 다양한 로봇 manipulation task와 여러 VLA architecture 전반에 걸쳐, VLA-Pruner는 계산량을 줄이면서도 성능을 유지함을 보입니다.