논문 주소: https://arxiv.org/pdf/2509.23224
ABSTRACT
효율성과 temporal coherence를 향상시키기 위해 Vision-Language-Action 모델은 종종 action chunk를 예측하지만, 이러한 action chunking은 inference delay와 long horizon 상황에서 반응성을 저하시킵니다. 이를 해결하기 위해, Asynchronous Action Chunk Correction(A2C2)를 도입합니다. A2C2는 모든 control step 마다 실행되는 lightweight real-time chunk correection head로서, 어떤 off-the-shelf VLA의 action chunk에도 time-aware correction을 추가합니다.
이 모듈은 최신 observation, VLA가 예측한 base action, chunk 내에서 base action의 index를 인코딩하는 positional feature, 그리고 base policy의 일부 feature를 결합하여 step 별 correction 값을 출력합니다. 이 방식은 base model의 능력을 유지하면서 closed-loop responsiveness를 회복합니다. 또한, base policy 재학습할 필요가 없고 Real time Chunking(RTC)과 같은 비동기 실행 방식과도 독립적입니다.
dynamic KINETIX task suite(12개 task)와 LIBERO SPATIAL 실험에서, 이 방법은 delay 증가와 horizon 증가 전반에서 일관된 success rate 향상(+23%p 및 +7%p, RTC 대비)을 보였으며, delay를 주입하지 않은 상황에서도 긴 horizon에서의 강건성을 개선합니다. 이러한 결과는 A2C2가 고용량 chunking policy를 real-time control 환경에 배치하기 위한 효과적인 plug-in 메커니즘임을 보여줍니다.
1 INTRODUCTION
최근 대규모 VIsion- Language-Action 모델의 발전은 로봇이 다양한 작업과 환경에 대해 일반화 하는 능력을 크게 확장시켰습니다. 그러나 모델 규모가 커질수록 각 step에서 action을 출력하는 데 필요한 계산량이 증가하며, 이는 높은 inference latency로 이어집니다. 특히 dynamic control 상황에서는 이러한 delay가 치명적입니다. 오래된 observation 기반으로 길게 예측된 action sequence에 의존할 경우 로봇은 drift가 발생하거나 중요한 단서를 놓치며, 빠른 반응이 필요한 작업(예: 움직이는 물체 집기, 불안정한 시스템 안정화)에 실패할 수 있습니다.
Foundation model 기반으로 neural network policy를 확장하는 추세는 더 나은 표현력을 제공하지만, latency를 동반합니다. π0 또는 OpenVLA와 같은 대규모 VLA 모델은 수십억 개의 파라미터를 갖고 있으며, 단일 action chunk를 생성하는 데 수백 ms가 걸리기도 합니다. 이러한 action chunk는 이전 observation만을 기법으로 open-loop 방식으로 실행되며, 실행 중 새롭게 들어오는 sensor 정보는 반영되지 않습니다. 따라서 latency는 단순히 실행을 지연시키는 문제에 그치지 않고, 최신 observation을 action에 반영하지 못하게 하여 반응성을 저하시킵니다. 예를 들어, 복잡한 테이블위에서 움직이는 물체를 따라가거나 주변에서 물건이 계속 놓이는 상황에서 식기률를 잡아야 할 때, 로봇은 최신 sensor inputs을 기반으로 action sequence를 조정해야 합니다. 하지만 outdated observation에서 계산된 action들은 시간이 지날수록 오차가 누적되기 때문에 성공률이 낮아지고 작업 실패로 이어질 수 있습니다. 이것이 본 연구가 다루는 핵심 문제입니다.
일반적인 접근 방식은 action chunking을 통해 대규모 모델의 latency 문제를 완화하려는 것입니다. 긴 action sequence를 한 번에 예측함으로써 고 비용 inference 호출의 빈도를 줄이는 방식입니다. 그러나 chun ing은 자체적으로 성능 문제를 초래합니다. inference 중 로봇이 기다려야 하는 시간이 생기고, chunk 간 불연속성도 발생할 수 있습니다. 이를 해결하기 위해 SmolVLA는 synchronous execution을 제안하고, Real Time Chunking(RTC)은 diffusion 기반 action generation에서 chunk 간의 연속성을 개선합니다. 하지만 이러한 방법들도 여전히 fixed-length horizon을 예측한다는 가정에 머물러 있어, 새로운 observation에 대한 반응성 문제를 완전히 해결하지는 못합니다.
또 다른 접근법은 dual-system reasoning에 영감을 받은 hierarchical architecture을 도입하는 것입니다. 대규모 모델이 high-level planner(system 2)의 역할을 하고, 작은 policy가 fast executor (System 1)로 동작하는 구조입니다. 예를 들어 Hi Robot은 high-level에서 VLM을, low-level에서 VLA를 결합하고, GR00T-N1은 compact policy로 연속적인 action chunk를 보정합니다. 그러나 low-level executor는 high-level 모델의 출력을 기다려야 하므로 latency 문제는 여전히 해결되지 않습니다. 즉, chunking이나 hierarchical approach는 일부 문제를 완화하지만, 많은 파라미터를 가진 VLA의 본질적인 inference delay로 인해 새로운 observation에 대한 responsiveness를 유지하는 데 근본적인 해결책이 되지 못합니다.
이 문제를 해결하고자, 본 연구에서는 Asynchronous Action Chunk Correction(A2C2)을 제안합니다. A2C2는 대규모 VLA 모델의 출력을 보완하기 위해 매 timestep마다 실행될 수 있는 lightweight correction head 입니다. 기존의 action chunking이나 asynchronous inference 방식과 달리, 본 방법은 high-level 모델이 출력한 action chunk를 참조하여 최신 observation을 직접 통합하는 lower-level correction layer를 도입합니다. 이 correction head는 diffusion-based 또는 VLA-based chunk generator와 경쟁하지 않고, inference delay와 긴 horizon에서 resonsiveness를 유지하기 위해 real-time feedback을 주입함으로 써 이를 보완합니다. 이러한 설계를 통해 제안된 프레임워크는 동적 환경 변화나 외부 교란에 대해 강건성을 획득하고, 대규모 VLA 모델을 실제 real-time control 환경에 배치할 때 발생하는 latency bottleneck을 완화합니다.
Kinetix tasks 실험 결과, delay가 있는 상황에서 naive 실행 대비 성공률이 35%p 증가하였고, RTC 대비 23%p 증가하였다. 긴 horizon에서는 naive 대비 12%p, RTC 대비 7%p 성공률 향상을 보였습니다.
본 연구의 기여는 다음과 같습니다:
- VLA가 action chunk를 생성할 때 발생하는 policy inference delay 문제를 최초로 정식화하였습니다.
- 어떠한 VLA 모델에도 독립적으로 적용 가능한 lightweight add-on action correction policy(A2C2)를 제안하여 반응성을 향상시켰습니다.
- 다양한 inference delay 환경에서 dynamic task와 robot manipulation benchmark에서 성공률을 크게 향상시켰습니다.
2 PROBLEM FORMULATION

본 연구에서는 imitation learning 기반 policy가 action chunk를 실행한느 상황을 고려합니다. 위 그림 1에서 보이듯, action chunk $A_t = {a_t, \ldots, a_{t+H-1}}$ 는 observation $o_t$와 language instruction $l$을 입력으로 하는 IL policy $\pi$로부터 생성됩니다. $H$는 IL 모델 $\pi$의 학습 시 사용된 chunk horizon 길이입니다. Agent는 action chunk 중 앞의 $e$ step을 실제로 사용하며, 이를 execution horizon 이라 정의합니다. Policy는 매 $e$ step 마다 action chunk를 다음과 같이 예측합니다:
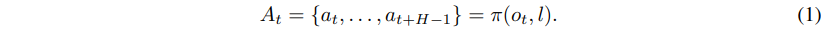
추가적으로 inference latency가 존재합니다. delay $d$는 observation $o_t$를 받은 시점부터 해당 action chunk $A_t$가 도착할 때까지의 control step 수로 정의합니다. 즉

다음과 같습니다. 여기서 $\delta$는 inference 및 통신이 포함된 총 지연 시간이며, $\Delta t$는 하나의 control step의 시간입니다.
지연된 chunk 실행을 수행하는 과정에서, 에이전트는 새로운 chunk가 비동기적으로 도착할 때 까지 매 step에 하나의 action만을 실행합니다. 또한 policy server는 한 번에 하나의 inference만 처리한다고 가정합니다. 만약 execution horizon $e$가 delay $d$보다 짧다면, inference 동안 실행할 action이 없어져 대기 시간이 발생합니다. 반대로 , $e$가 $H-d$보다 길면 inference 중 실행할 action이 남아있지 않은 문제가 발생합니다. 따라서 execution horizon은 다음 과 같은 조건을 만족해야 합니다.

이러한 설정에서 에이전트가 사용하는 action은 항상 과거 observation 기반입니다. 실행 되는 모든 action은 최소 $d$ step 이전의 observation에 기반하며, 최악의 경우 $d + e$ step 이전 observation 기반의 action을 실행하게 됩니다.
3. METHOD

3.1 OVERVIEW
본 연구에서는 action chunk 기반 policy $\pi$를 확장하여 Asynchronous Action Chunking Correction(A2C2)를 도입합니다. 이는 lightweight correction head $\pi_{\text{a2c2}}$로서, 예측된 action chunk 내 각 action을 최신 observation, base policy의 feature, temporal position feature을 이용해 보정합니다. 이 구조는 base policy를 재학습하지 않고도 step-wise correction을 가능하게 하며 RTC 등 기존 기법들과 상호 보완적으로 동작합니다.
시간 $t$에서 observation $o_t$가 policy server로 전달되고, base policy $\pi$는 delay $d$ 이후 다음과 같은 action chunk를 출력합니다:
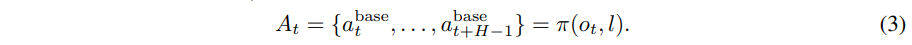
이후 시간 $t+k$ ($d \le k \le d+e$)에서 correction head $\pi_{\text{a2c2}}$는 다음 요소들을 입력으로 사용합니다:
- positional feature $\tau_k$
- base action $a^{\text{base}}_{t+k}$
- 최신 observation $o_{t+k}$
- base policy의 최신 representation $z_{t+k}$
- instruction $l$
positional feature $\tau_k$는 chunk 내 위치 정보를 주기적으로 부여하기 위해 다음과 같은 sinusoidal embedding을 사용합니다:

Correction head는 이 정보를 통합해 residual action $\Delta a_{t+k}$를 예측하며, 다음으로 정의됩니다:
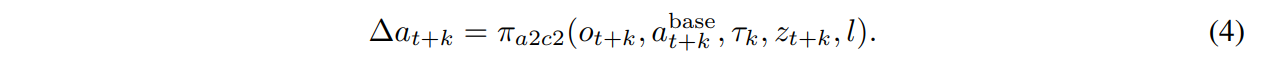
최종 실행 action은 다음과 같이 계산됩니다:

base policy $\pi$는 $e$ step 마다 delay $d$를 두고 새로운 chunk를 생성합니다. 반면, correction head $\pi_{\text{a2c2}}$는 모델 크기가 작아 하나의 control step 기간 $\Delta t$ 내에서 매 step 실행될 수 있다고 가정합니다.
본 방법의 주요 특징은 다음과 같습니다:
- Time-aware correction: chunk 내 위치 정보를 명시적으로 조건으로 사용한다.
- Chunk-level smoothness: 어떤 chunk element를 보정하는지 명확히 하여 horizon 전반에 걸친 smooth correction을 유도한다.
- Data compatibility: correction head는 base VLA policy를 학습한 동일한 demonstration dataset으로 학습 가능하며, RL 기반 fine-tuning이 필요 없다.
- Real-time feedback: 항상 최신 observation을 반영하여 inference delay가 있는 dynamic task에서도 robustness를 향상한다.
3.2 MODEL TRAINING PROCEDURE
먼저 base policy $\pi$는 다음 dataset으로 학습됩니다:

이후 base policy $\pi$로부터 각 step에서 action chunk의 inference 결과를 구합니다:

이를 기반으로 correction head 학습을 위한 새로운 dataset을 구성합니다:

여기서 $\hat{a}^k_{t-k}$는 base policy가 시간 $t-k$의 observation으로부터 생성한 action chunk의 $k$번째 action입니다. Correction head $\pi_{\text{a2c2}}$는 target action과 base policy action의 차이를 예측하도록 학습된다. 즉, residual target은 다음과 같습니다:

예측된 residual acrtion을 $\Delta \hat{a}_{\text{residual}}$라 할 때, loss는 MSE로 정의됩니다:

여기서 $N$은 mini-batch의 sample 수입니다.
4 EXPERIMENTAL SETUP
4.1 BENCHMARK AND DATASETS
본 연구에서는 두 개의 시뮬레이션 환경인 Kinetix와 LIBERO Spatial을 사용하여 실험을 수행하였습니다. Kinetix는 매우 동적인 manipulation 및 locomotion task 평가를 위해 ㅁ너저 사용되었으미, LIBERO Spatial은 로봇 manipulation의 표준 benchmark로서 성능 평가에 활용되었습니다. 특히 이전 논문에서는 LIBERO Spatial에서 long-horizon이 성능 저하를 크게 유발함을 보고하였기 때문에, 본 과업은 long-horizon 조건에서의 robustness를 평가하기에 적합합니다.
4.1.1 KINETIX
Kinetix는 Appendix A.1에 제시된 바와 같이 12개의 매우 동적인 task에 대해 demonstration을 제공하는 환경입니다. Locomotion과 grasping부터 game-like 환경까지 다양한 task를 포함하며, 비정적(quasi-static)이 아닌 환경들이 많기 때문에 action chunking 구조에서 delay 또는 inconsistency가 발생하면 빠르게 failure로 이어집니다. 이러한 특성 때문에 inference-time algorithm(예: RTC)의 latency 대응 능력을 평가하기 위한 자연스러운 testbed 역할을 합니다.
또한 Kinetix는 torque 및 force 기반 actuation을 사용하므로 asynchronous inference가 특히 중요하다. Kinetix는 언어 입력이 없는 12개 task로 구성됩니다. 전문가 모델을 이용하여 총 100만 step의 데이터를 수집하였습니다. RTC 실험과 동일하게, 먼저 RPO와 binary success reward를 통해 expert policy를 학습하였고, 각 환경에 대해 expert policy를 사용하여 100만 transition dataset을 구축하였습니다.
4.1.2 LIBERO
LIBERO는 lifelong robot learning을 목표로 하여 task 간 knowledge transfer를 연구하기 위해 설계된 benchmark suite입니다. 여러 task suite과 dataset을 제공하며, 본 연구에서는 manipulation task에서 spatial reasoning이 중요한 LIBERO Spatial dataset만을 사용하였습니다.
3D 로봇 manipulation benchmark로서 LIBERO Spatial을 활용하였으며, 총 432개의 episode, 52,970개의 frame, 10개 task로 구성된다. Dataset은 top 및 wrist RGB 이미지(256×256), 8차원 state, 그리고 language instruction 등 multimodal 입력으로 구성됩니다.
4.2 MODEL TRAINING
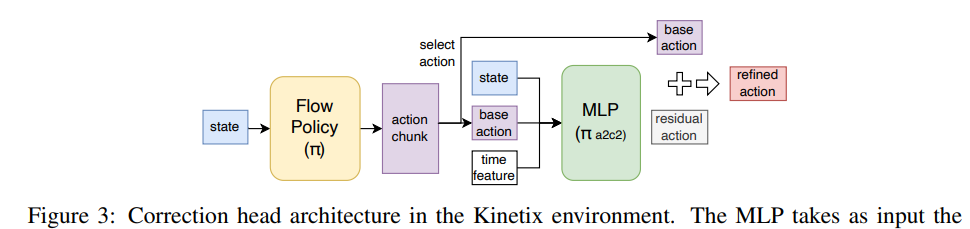
Kinetix에서는 prior work에 따라 flow-matching policy를 base model로 사용하였습니다. Correction head는 3-layer MLP이며, 입력은 다음 요소를 concatenation하여 구성됩니다:
- state vector (2722-dimensional)
- base action (6-dimensional)
- sinusoidal positional feature (2-dimensional)
언어 instruction이나 base policy의 latent representation은 사용하지 않았습니다. Kinetix는 task별로 독립적으로 학습・평가되기 때문입니다.
Hidden layer는 각각 512 units이며, 활성화 함수로 ReLU , 그리고 layer normalization을 사용하였습니다. Output layer는 6-dimensional residual vector를 생성하며, 이는 base action에 element-wise로 더해집니다. 전체 parameter 수는 0.31M이다. Figure 3은 Kinetix 실험의 구현 세부 내용을 보여줍니다.
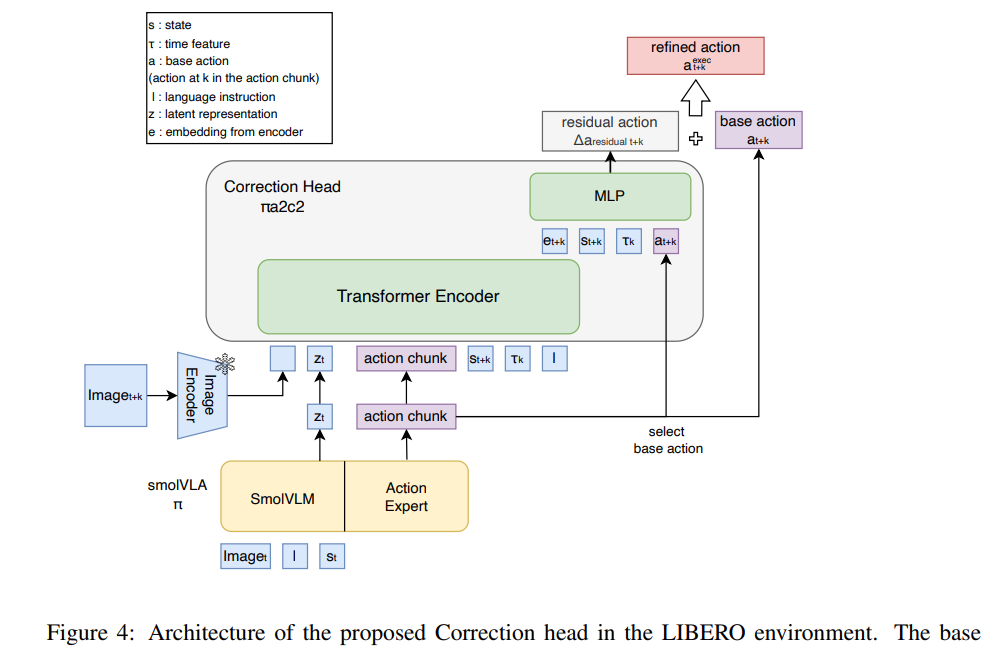
LIBERO Spatial에서는 VLA 모델 중 경쟁력이 높은 SmolVLA를 base policy로 사용하였습니다. Correction head는 transformer encoder와 lightweight MLP로 구성됩니다.
처리 과정은 다음과 같습니다:
- Top 및 wrist camera의 RGB 관측값은 ImageNet으로 pretrain된 ResNet-18을 통해 512-dimensional token으로 인코딩된다.
- Language instruction은 base policy에서 제공하는 smolVLM encoder로 임베딩된다.
- Base action, base policy latent feature, sinusoidal time embedding 역시 512-dimensional token으로 projection된다.
- 모든 token을 concat하여 6-layer transformer encoder에 입력한다.
- Encoder의 pooled embedding과 base action, state vector를 3-layer MLP(hidden size 512)에 입력하여 residual action을 예측한다.
전체 파라미터 수는 32M 입니다. 그림 4는 실험 구현 구조를 보여줍니다. Kinetix와 LIBERO 실험을 위한 source code는 공개되며, 세부 내용은 Appendix A.3에 기술되어 있습니다.
5 RESULTS
5.1 KINETIX
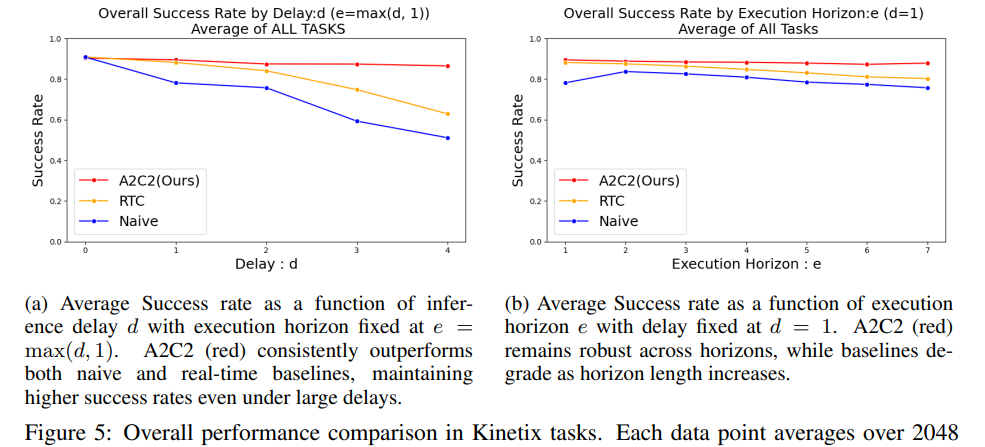
본 연구에서는 Kinetix benchmark에서 다양한 inference delay dd 와 execution horizon ee 조건 하에서 제안한 action chunk correction framework를 평가하였습니다. Figure 5는 12개 전체 task에 대한 success rate를 집계하여 보여줍니다. 비교 대상 baseline은 두 가지 입니다. 첫 번째는 Naive async로, 이는 새로운 action chunk가 도착하면 기존 chunk와의 연속성을 전혀 고려하지 않고 즉시 교체하는 방식입니다. 두 번째는 RTC이다.
예상대로, delay dd 가 증가하거나 horizon HH 가 길어짐에 따라 naive async와 RTC baseline 모두 성능이 크게 저하되었습니다. 특히 d≥3d \ge 3 조건에서는 outdated action chunk 실행으로 인한 누적 오류 때문에 naive baseline의 success rate가 급격히 감소하였습니다. RTC inference는 prediction과 execution을 부분적으로 중첩하여 이러한 문제를 완화하지만, execution horizon이 증가할수록 성능 저하는 여전히 발생합니다.
반면, action chunk correction은 모든 설정에서 일관되게 더 높은 success rate를 유지하였습니다. 이는 correction head가 최신 observation을 매 step 반영하여 각 action을 refinement하기 때문에, inference delay로 발생하는 temporal misalignment와 긴 action horizon 내에서 누적되는 drift를 모두 보정할 수 있기 때문입니다. 예를 들어 delay d=4d = 4 조건에서 제안한 방법은 naive baseline 대비 약 35% 더 높은 성공률을 달성하였고, horizon H=7H = 7에서도 85% 이상의 성능을 유지하였습니다. 이는 real-time correction이 delay와 long-horizon 상황 모두에서 성능을 유지하는 데 효과적임을 보여줍니다.
5.2 LIBERO SPATIAL
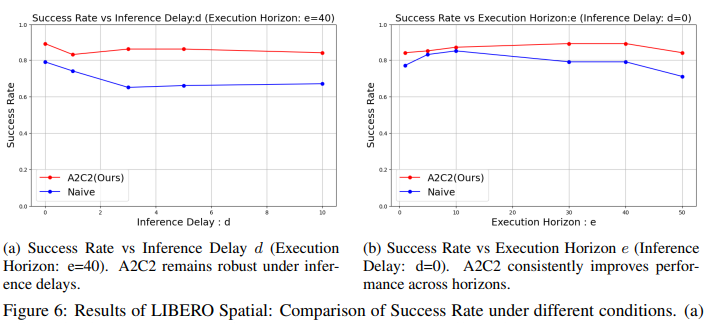
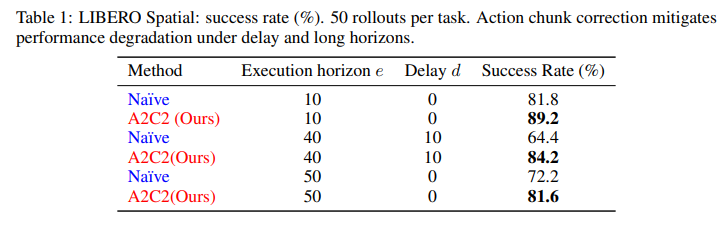
Figure 6 및 Table 1은 LIBERO Spatial benchmark에 대한 평가 결과를 요약한 것입니다.이 설정에서 Naive async와 A2C2를 비교하였다. Multimodal 입력을 사용하는 10개 manipulation task 전반에서 correction head는 long horizon과 delay가 삽입된 조건 모두에서 naive baseline 대비 일관적으로 더 높은 success rate를 보였습니다.
예를 들어 execution horizon H=40H = 40, delay d=10d = 10 조건에서 naive baseline은 67%의 성공률을 보였으나, A2C2는 84%에 도달하였습니다. Delay가 전혀 없는 상황에서도 H=50,d=0H = 50, d = 0 조건에서 action chunk correction은 success rate를 72.2%에서 81.6%로 향상시켰습니다.
이 결과는 correction head를 통한 residual refinement가 outdated action chunk로 인해 발생하는 성능 저하를 효과적으로 완화하고 closed-loop responsiveness를 회복함으로써, large VLA 모델이 정교한 spatial reasoning이 필요한 task에서도 높은 success rate를 유지할 수 있게 함을 보여줍니다.
6 RELATED WORK
Imitation learning과 VLAs
Imitation learning은 인간 또는 expert policy가 제공한 demostration으로부터 agent를 학습시키는 방식이며, 로봇 제어를 위한 대표적인 접근 방식으로 연구되어 왔습니다. 최근에는 generative sequence model을 도입하여 일관성과 확장성을 향상시키는 방법이 제안되었습니다. Diffusion Policy는 diffusion model을 통해 action을 생성하며, imitation learning 데이터의 multimodality를 처리할 수 있게 합니다. 한편, Action Chunking Transformer(ACT)는 single-step action 대신 action chunking을 출력하는 trasnformer 기반 policy를 제안하여, 더 일관된 행동 생성과 빠른 inference를 동시에 달성합니다. 추가적으로 Flow Policy와 같은 flow-based 접근 방식은 iterative denoising 대신 continuous transport map을 학습하여 action을 생성합니다.
이러한 기반 위에서 π0, OpenVLA, GR00T, SmolVLA 등 새로운 vision–language–action(VLA) foundation model 계열이 등장하였습니다. 이들 모델은 ACT와 유사하게 chunk-based prediction을 inference의 기본 구조로 채택하고 있습니다. VLA 모델들은 multimodal 입력 정렬을 통해 매우 넓은 범위의 task generalization을 달성하지만, diffusion 또는 일반 transformer imitation policy 대비 훨씬 큰 모델 규모를 가집니다. 예를 들어, π0는 약 3B parameters, OpenVLA는 약 7B parameters 규모를 가지며, 이러한 대규모 구조는 최신 GPU 환경에서도 상당한 inference latency를 초래합니다. 즉, scaling의 장점을 활용하는 동시에 실시간 제어에서 latency 문제가 더욱 심화되는 구조적 한계가 존재합니다.
Asynchronous chunk execution
모델 규모가 커질수록 inference latency가 심각한 병목으로 작동하며, 이를 완화하기 위한 asynchronous policy framework가 제안되어 왔습니다. SmolVLA는 inference delay를 완화하기 위한 server–client 구조를 제안하였습니다. 서버는 observation을 받아 dd step의 delay 동안 inference를 수행한 뒤, horizon HH 길이의 action chunk를 client에게 전달합니다. Client는 새 chunk가 도착할 때까지 이전 chunk의 action을 계속 실행하여 연속성을 확보합니다.
그러나 이 구조는 연속적인 chunk 간 불일치 문제를 야기한다. 예를 들어 이전 chunk는 장애물을 피하기 위해 왼쪽으로 이동을 예측한 반면, 새 chunk는 오른쪽 이동을 제안할 수 있습니다. 이러한 chunk mismatch는 특히 dynamic 환경에서 jerky motion과 성능 저하로 이어집니다.
이를 해결하기 위해 Real Time Chunking(RTC)이 도입되었다. 이는 action-chunking policy를 위한 inference-time 알고리즘으로, chunk switching 문제를 inpainting 문제로 재정의합니다. 즉, 현재 chunk를 실행하는 동안 다음 chunk 일부를 생성하고, 이미 실행이 보장된 action은 고정(freeze)하고 나머지 구간을 inpaint하는 방식입니다.
Reducing inference latency
실시간 성능을 개선하는 직관적인 방법은 모델의 inference 시간을 단축하는 것입니다. Streaming Diffusion Policy나 Streaming Flow Policy는 더 빠른 inference를 가능하게 하는 새로운 training 절차를 제공합니다. 또한 model compression이나 memory optimization과 같은 일반적 최적화 기법 역시 inference 속도를 개선할 수 있습니다. 그러나 모델 규모와 통신 지연이 control step보다 빠른 action 생성 속도를 막는 한, 본 연구에서 제기된 문제는 여전히 해결되지 않습니다.
7 CONCLUSION
본 논문에서는 대규모 VLA 기반 정책을 augmentation하여 lightweight correction head를 도입하는 Asynchronous Action Chunk Correction(A2C2)을 제안하였습니다. A2C2는 action chunking 정책이 갖는 inference delay와 long execution horizon 상황에서도 reactivity를 유지하기 위한 구조로 설계되었습니다. Correction head는 base policy와 동일한 dataset으로 학습되며, 어떠한 off-the-shelf VLA 모델에도 추가할 수 있습니다.
Kinetix와 LIBERO Spatial benchmark의 실험 결과, A2C2는 naive 방식과 RTC가 심각하게 성능이 저하되는 조건에서도 높은 success rate를 일관적으로 유지하였습니다. Correction head는 base policy 전체를 재학습하는 방식이 아니므로 전체 inference 대비 매우 작은 overhead만 추가되지만, 향후 더 복잡한 language instruction, out-of-distribution 환경, 보다 동적인 task까지 확장해 검증하는 작업이 필요합니다. 이는 action chunk correction의 실용성을 더 넓은 영역으로 확장하는 데 도움이 될 것입니다.
최근 LLM과 VLM은 neural scaling law를 기반으로 parameter scaling을 통해 일반화 능력을 크게 향상시키고 있습니다. VLA 계열 정책도 이러한 모델들을 기반으로 구축되므로, 향후 다양한 환경과 task에서 배치를 위해 더 큰 규모로 확장될 가능성이 높습니다. 본 연구는 이러한 대규모 VLA가 inference latency 문제로 인해 responsiveness를 잃지 않도록 돕는 하나의 방향성을 제시한다고 볼 수 있습니다.
또한, 수십억 단위 parameter 모델의 inference는 대부분의 로봇 플랫폼에서 on-board inference를 수행하기에는 계산 자원이 부족합니다. 실제로는 remote server에서 VLA를 실행하고 robot이 이를 네트워크로 query하는 client–server 구조가 일반적입니다. 본 논문은 communication delay를 inference latency의 일부로 명시적으로 고려하였기 때문에, 이러한 구조에도 자연스럽게 적용됩니다.
따라서 본 연구는 대규모 VLA의 generalization 능력을 그대로 유지하면서도 실세계 배치에서 필요한 responsiveness를 제공하는 lightweight correction 구조를 제안함으로써, 향후 확장 가능한 VLA 시스템 설계에 중요한 기반을 마련합니다.
