논문 주소: https://arxiv.org/pdf/2505.11563
Abstract
Visual representation은 로봇 조작 policy의 학습과 일반화 능력에서 핵심적인 역할을 수행합니다. 기존 방법들은 global feature 또는 dense feature에 의존하는 경우가 많지만, 이러한 representation은 task-relevant 정보와 irrelvant한 scene 정보를 함께 얽어 표현하는 경우가 있어, distribution shift 하에서는 강건성을 제한합니다. 본 연구에서는 visual input을 유한한 entity의 잡합으로 분해하는 구조적 대안으로서 object-centric represenatation(OCR)을 탐구하며, 이는 조작 task의 특성과 보다 자연스럽게 정렬되는 inductive bias를 도입합니다. 본 연구에서는 object-centric,global, dense 방식의 다양한 visual encoder를 대상으로, 단순한 task부터 복잡한 task에 이르는 시뮬레이션 및 실세계 로봇 조작 task set 전반에서 성능을 비교 평가하고, 조명, texture 변화, distractor 존재 등 다양한 시각적 조건 하에서의 일반화 능력을 분석합니다. 그결과 OCR 기반 policy는 task-specific pretraining이 없더라도, generalization 환경에서 dense 및 global representation을 일관되게 상회하는 성능을 보임을 확인하였습니다. 이러한 결과는 OCR이 동적이고 실세계적인 로봇 환경에서 효과적임을 일반화하는 visual system을 설계하는 데 있어 유망한 방향임을 시사합니다.
Introduction
Visumotor policy learning은 로봇이 raw visual sensory input을 제어 action으로 직접 매핑할 수 있도록 하여, 환경을 인식하고 상호작용하게 합니다. 핵심 목표는 generalization하면서도 sample-efficient한 polcy를 학습하도록 하는 것입니다. 현재까지의 state-of-the-art 접근법들은 imitation learning을 통해 visuomotor policy를 위해 공통적인 아키텍처 구성을 채택해 왔으며, 학습 과정을 sensor encoding module, 서로 다른 modality를 통합하는 observation trunk, 그리고 최종 action을 예측하는 action head로 구분됩니다. 이 과정의 성공을 좌우하는 핵심 요소는 visual representation의 품질로, 이는 task-relevant feature를 포착하는 동시에 환경 변화에 대해 강건해야 합니다.
이에 따라 최근 연구들은 generalizable한 로봇 policy를 가능하게 하는 데 있 어 visual representation의 역할에 점점 더 주목하고 있습니다. 이러한 발전에는 대뮤고 인간 egocentric video dataset에 대해 time-contrastive 및 language-aligned objective를 사용한 pre-training, 다양한 vision foundation model로부터 지식을 compact하고 robot-friendly한 encoder로 distillation하는 방법, 그리고 masked autoencoding과 같은 강력한 self-supervised scheme의 활용이 포함됩니다. 그럼에도 붌구하고, 대부분의 기존 적븐법은 공통된 아키텍처 계보, 주로 Resnet 이나 ViT에 의존하며, encoder의 마지막 layer에서 global feature vector(holistic)또는 dense patch-based reprewsentation으로 visual scene을 인코딩합니다. 이러한 representation은 종종 task-relevant 정보와 irrelevant 정보를 함께 얽어 표현하여, 조명 변화, 새로운 texture, cluttered enviroment와 같은 실세계 변화에 매우 취약해집니다. 이는 인간의 지각 방식과 분명히 대조되는데, 인간은 복잡한 환경을 이해하고 행동할 때 주변 세계에 대한 symbolic representation을 형성합니다. 본 연구에서는 raw seneory data를 고립적으로 처리하기 보다는, 의미 있는 entity—“mental symbol”—를 추상화하고 이를 구조적이고 재사용 가능한 개념으로 reasoning합니다. 이러한 compositional 이해는 과거 경험을 바탕으로 새로운 미지의 상황에 빠르게 일반화할 수 있게하며, 그 핵심에는 정보를 disentangle하고 bind하며, 유연하게 조작하느 능력이 있습니다. 이러한 특성은 오늘날의 인공 시스템에서는 여전히 구현하기 어려운 요소로 남아 있습니다.
로봇 분야에서는 perception과 control 사이의 간극을 메우기 위해, 구조, 추상화, 그리고 task-relevance를 강조하는 방향으로 visual scene representation을 재고해야 한다는 증거가 점점 축적되고 있습니다. 이러한 능력을 향한 유망한 접근 중 하나는 CV 분야에서 최근 부상한 object-centric representation(OCR)입니다. 이러한 방법들은 이미지를 object라는 entity 집합으로 분할함으로써 재구성하며, symbolic하고 compositional한 reasoning에 부합하는 inductive bias를 내재화합니다. OCR은 visual pipeline에 구조를 도입하여, 모델이 scnee을 의미 있는 부분으로 분해하고 이를 명시적으로 reasoning할 수 있도록 합니다. 특히, 이러한 접근은 인간이 세계를 인식하고 상호작용하는 방석, flat한 pixel 배열이 아니라, 추적 및 조작을 가능하게 하며 개념으로 추상화 될 수 있는 독립적인 entity들의 집합으로 이해하는 방식과 유사하다고 할 수 있습니다. 이러한 관점에서, object-centric perception은 로봇 조작을 위한 low-level visual input과 high-level symbolic reasoning 사이의 간극을 메우는 하나의 경로를 제공할 수 있습니다.
로봇 분야에서 OCR의 잠재력은 점차 인식되고 있으나, 기존 연구의 상당수는 image decomposition이나 scene reconstruction에서의 활용에 초점을 맞추어 왔습니다. 최근 일부 연구에서는 reinforcement learning task를 중심으로 control에서의 역할을 탐구하였지만, 이러한 연구들은 대체로 매우 단순화된 toy setting에 국한되어 있습니다. 그 결과, 당므과 같은 핵심 질문들은 여전히 열려 있습니다.
Q1: OCR model은 다른 visual representation에 비해 로봇 조작 policy learning을 더 잘 가능하게 하는가?
Q2: OCR은 distractor, 새로운 texture, 다양한 조명 조건이 존재하는 상황에서 policy generalization 능력을 향상시킬 수 있는가?
이러한 질문에 답하기 위해, 본 연구에서는 당므과 같은 기여를 제시합니다.
- 로봇 조작을 위한 다양한 유형의 visual reprensentation을 평가할 수 있는 통합 프레임워크를 개발하고 이를 open-source로 공개합니다. 본 연구에서는 global, dence, object-centric representation을 포함한 7개의 서로 다른 visual encoder를 대상으로, 두 개의 시뮬레이션 환경과 새롭게 제안하는 손쉽게 재현 가능한 실세계 task 세트 전반에서 benchmark를 수행합니다.
- 기존 연구와 달리, slot-based object representation이 task-specific tuning 없이도 로봇 조작 policy learning을 향상시키고, 특히 현실적인 distractor와 domain shift 환경에서 로봇 제어의 generalization을 개선함을 보입니다.
Related Works
Pretrained vision based models for robot learning
최근 몇 년간 computer vision 분야에서는 visual representation 학습을 위한 대규모 pretraining 전략이 발전하였고, 그 결과 MoCo, DINO, DINOv2, CLIP과 같은 모델들이 등장하였습니다. 이들 모델은 본래 classification이나 image-text alignment을 위해 학습되었지만, domain-specific한 로봇 데이터에 접근하지 않더라도 로봇 분야의 downstream visumotor policy learning에서 놀라울 정도로 효과적임이 보고 되었습니다.
Visual representation을 manipulation task에 더 잘 정렬시키기 위해, 후속 연구들은 manipultation 관점에서 보다 높은 데이터셋과 학습 objective를 활용한 pretraining을 탐구하였습니다. R3M은 대규모 human egocentric video(Ego4D)를 기반으로 time-contrastive learning, video–language alignment, sparsity regularization을 결합하여 학습함으로써, simulation과 실세계 모두에서 효율적인 imitation learning을 가능하게 하였습니다. VC-1은 masked autoencoding과 mixed-domain training(ImageNet과 로봇 비디오)을 결합하였으며, Theia는 CLIP, SAM, DINOv2와 같은 여러 vision foundation model을 distillation하여 로봇 policy learning에 최적화된 compact transformer backbone을 구축하였습니다.
한편 최근 연구들은 로봇이나 manipulation-specific 데이터셋이 항상 더 나은 pretraining으로 이어지는지에 대한 의문을 제기하였습니다. Dasari 등은 ImageNet, Kinetics, 100 Days of Hands와 같은 curated general-purpose 데이터셋이, 동일한 architecture와 objective를 사용하더라도 Ego4D나 RoboNet보다 visuo-motor pretraining에서 더 우수한 성능을 보이는 경우가 많다는 것을 보였습니다. 이 연구는 데이터셋의 크기나 domain 일치 여부보다 image distribution의 품질과 다양성이 더 중요함을 보여주었으며, egocentric manipulation 데이터가 로봇학습에 더 적합하다는 통념이 실제로는 성립하지 않을 수 있음을 시사하였습니다. 유사하게, 또 다른 연구에서는 강한 emergent object segmentation 특성을 지닌 vision transformer가 좀여 변화, texture 변화, distractor 존재와 같은 distribution shift하에서 더 잘 일반화함을 보여주었습니다.
이러한 결과들은 로봇 학습을 위한 visual representation을 재고할 필요성을 재기하며, flat한 global feature나 dense feature map에서 벗어나 보다 구조적인 대안을 모색하도록 동기를 부여합니다. 특히 visual input을 개별 entity로 분할하는 object-centric representation은 task-relevatn한 구조를 보다 강건하고 compositional하게 포착할 가능성을 지닙니다. 본 연구는 이러한 방향을 기반으로, visual pretraining에서 object-centric bias를 도입하고, 이를 통해 visuomotor policy learning에서의 generalization과 robustness에 미치는 영향을 평가합니다.
Object-centric learning
Object-Centric Representation(OCR)은 이미지를 여러 벡터로 구성된 구조적 representation으로 분해하는 것을 목표로 하며, 이 때 각 벡터는 흔히 slot이라 불리는 추출된 entity에 대응합니다. 이러한 방법들은 autonomous driving, robotics, explainability 등 다양한 분야에서의 잠재적 이점으로 인해 최근 큰 관심을 받고 있습니다. 초기 OCR 연구는 주로 generative modeling 관점에서 구조적 represenatation 학습에 초점을 맞춰왔습니다. 이후 연구들은 encoder-decoder architecture를 채택하여 보다 구조적이고 disenteangled 된 latent space를 획득하는 방향으로 발전하였습니다. 이 분야에서 가장 대표적인 방법은 Slot-Attention으로, 단순성과 효율성 측면에서 널리 알려져 있습니다.
이후 diffusion model, transformer decoder와 같은 보다 강력한 decoding 메커니즘이 도입되었고, pre-trained backbone을 활용하여 실세계 환경에서의 OCR 성능을 향상시키려는 시도도 이루어졌습니다. 최근에는 recurrent neural network나 transformer architecture가 OCR 방법에 통합되어 video 입력에 적용 가능하도록 확장 되었습니다. OCR은 입력 이미지를 의미 있는 구성 요소로 자연스럽게 분할함으로 써 imitation learning에서의 generalization을 향상시킬 잠재력을 지니지만, 대부분의 연구에서는 image reconstruction 이나 semantic segmentation에 초점을 맞추어 왔으며, control task를 직접적으로 다룬 사례는 많지 않습니다. 일부 예외적으로, 단순한 control 환경에서 OCR을 적용한 연구들이 존재합니다.
본 논문의 목표는 이러한 고유한 segmenatation 능력을 내재한 OCR 방법들이 visumotor policy learning을 촉진하고, 로봇 조작 모델의 generalization을 향상시킬 수있는지 평가하는 데 있습니다.
Method
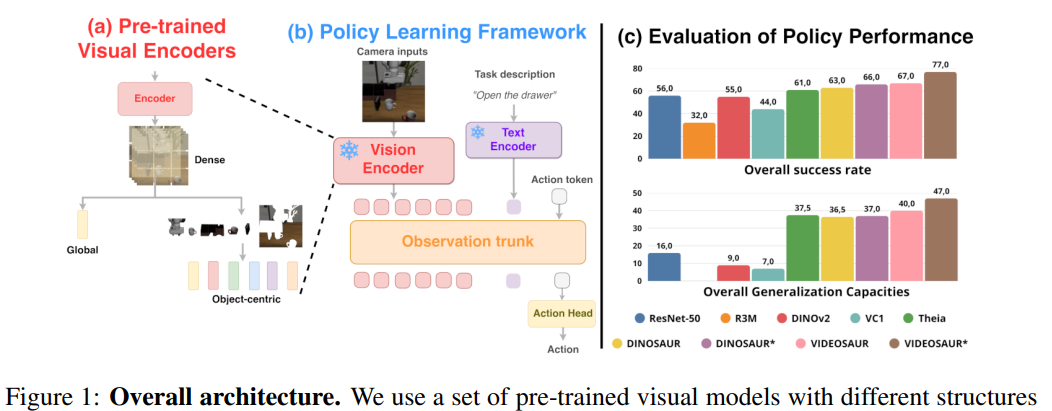
본 연구의 프레임워크의 개요는 위 그림 1에 있습니다. sensor encoding module(Vision encoder), 서로 다른 modality(예: instruction을 위한 text)를 통합하는 observation trunk, 그리고 최종 action을 예측하는 action head로 구성됩니다. 먼저, video를 위한 object-centric representation과 visual encoding을 위한 그 변형들을 소개한 뒤, policy learning을 설명합니다.
Object-centric representation for videos
Object-centric 방법은 object-level dynamic와 interaction을 모델링함으로 써 scene 전반에 걸친 generalization 능렧으로 CV 분야에서 주목을 받아왔습니다. 입력 이미지 $O$가 주어졌을 때, 목표는 object representation 집합 $S={s_1,\ldots,s_K}$를 생성하는 것입니다. 이미지는 먼저 vision backbone을 통해 dense feature 집합 $F={f_1,\ldots,f_N}$($N \gg K$)로 인코딩되며, 이후 Slot Attention을 사용하여 obejct specific representation $S$—즉 slots—을 추출합니다. Slot Attention은 경쟁을 포함한 iterative attention을 수행하는 미분 가능한 모듈로, 서로 다른 slot이 입력 scene의 서로 다른 부분을 표현하도록 특화되게 합니다. 개념적으로 Slot-Attention은 cross-attention module로 사용하며, Eq. (1)과 같이 query에 대한 재정규화를 적용합니다. 이후 attention weight를 사용해 Eq. (2)와 같이 value의 가중합으로 slot을 얻습니다:
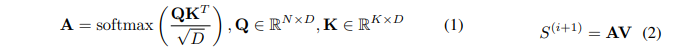
Eq. (1)의 query $Q$는 iteration $i$에서의 slot 집합 $S^{(i)}$를 projection한 것이며, key $K$와 value $V$는 dense feature $F$의 projection 입니다. 이 과정은 최종 slot을 얻기 위해 반복적으로 수행됩니다. 원래 Slot-Attention 모델은 단순한 Convolutional neural network를 visual backbone으로 사용하고, slot으로 부터 입력 이미지를 재구성하기 위해 단순한 Deconvolutional decoder를 learning signal로 사용하였습니다. 그러나 이 방법은 복잡한 이미지를 포함하는 실세계 시나리오에서는 한계가 존재합니다. DINOSAUR은 frozon DINO를 visual backbone으로 사용하며, 입력 이미지 대신 추출된 feature를 재구성합니다. VBIDEOSAUR는 DINOSAUR를 video로 확장하여 두 가지 주요 변경을 도입합니다. 첫째, timestep $t-1$에서 예측된 slot으로부터 timestep $t$의 slot을 초기화하기 위한 transformer predictor model을 추가합니다. 둘째, 연속된 두 timestep 에서 업데이트된 DINOv2 feature의 유사도를 활용한 temporal consistency loss를 추가합니다.
Policy training
본 연구의 주요 목적은 object-centric representaiton을 로봇 policy learning의 입력으로 사용할 때 효과를 평가하는 것이며, 보다 구체적으로 imitation learning framework로 이를 검증합니다. expert demonstration 집합 $D={\tau_1,\ldots,\tau_n}$가 주어질 때, 각 $\tau_i=[(o_0,a_0),\ldots,(o_T,a_T)]$로 구성되며, policy $\pi$는 입력 observation $o_t$(예: visual input)에서 다음 action $a_t$로 의 매핑을 학습해야 합니다. 공정한 비교를 위해, global, dense, slot-based 입력을 모두 처리할 수 있는 통합된 프레임워크 내의 policy architecture를 채택합니다. 또한, 기존 연국와 동일하게, policy training 과정 동안 사전 학습된 visual model은 freeze 합니다.
시뮬레이션 환경에서는 encoder, observation trunk, policy head로 구성된 BAKU architecture를 사용합니다. Observation trunk는 trasnformer 기반 모델로, 과거 $T$개의 observation 시퀀스를 인코딩합니다. 각 observation은 visual feature, language embedding, proprioceptive state를 포함하며, 학습 가능한 action token과 interleave됩니다. Policy head는 deterministic Multi-layer percetron으로, 최종 action token을 사용해 다음 action을 예측합니다. 실세계 실험에서는 LeRobot 라이브러리에 구현된 Action Chunking Transformers(ACT)를 기반으로 합니다. 원래 모델은 dense 입력 representation을 사용하였으며, 본 연구에서는 ACT의 입력 modality를 수정하여 단일 global visual feature vector 또는 object-centric slot vector 집합을 포함하도록 확장하였습니다. Multi-task learning을 지원하기 위해, ModernBERT model에서 도출한 task-specific language embedding을 visual 및 proprioceptive 입력과 concat 합니다. 이 결합된 representation은 transformer encoder-decoder를 통해 처리되어 action chunk를 생성합니다.
4 Benchmarks and Experimental setup
Environments and tasks
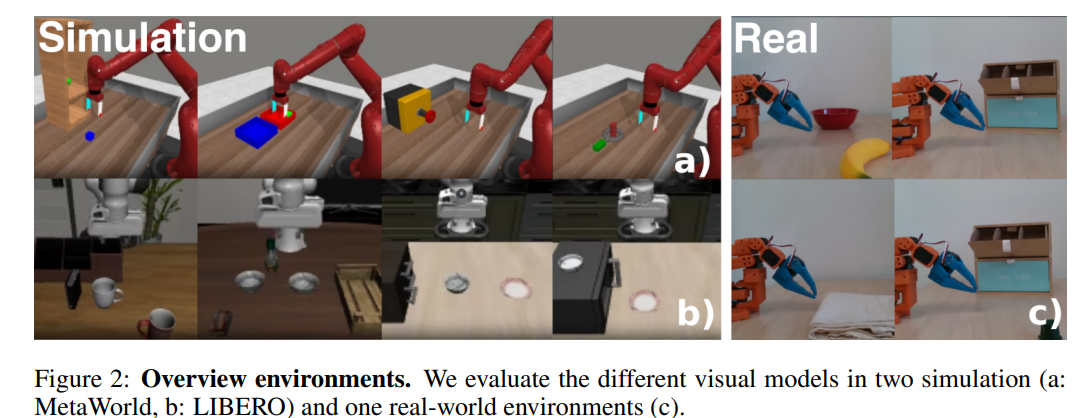
로봇 조작에서 visual representation을 종합적으로 평가하기 위해, Figure 2에 제시된 바와 같이 task 복잡도, embodiment, 그리고 visual 구조 측면에서 다양성을 갖는 세 가지 상호보완적인 환경—시뮬레이션 2종과 실세계 1종—을 선정하였습니다. 시뮬레이션 환경으로는 Sawyer 로봇 팔을 사용한 tabletop manipulation task로 구성된 well-established benchmark인 MetaWorld를 사용합니다. MetaWorld는 표준화된 task와 통제된 실험 설정을 제공하며, 구조화된 generalization 테스트를 지원하므로 단일 object 기반의 비교적 단순한 시나리오에서 representation 성능을 평가하기에 적합한 기준 환경입니다.
Object-centric representation의 확장성을 검증하기 위해, 최근 제안된 benchmark인 LIBERO-90을 추가로 포함합니다. LIBERO-90은 주방, 사무실, 거실 등 다양한 domain에 걸친 multi-object이며 시각적으로 복잡한 scene을 특징으로 합니다. LIBERO는 특히 multi-object reasoning과 새로운 object 조합에 대한 generalization을 강조하므로, object-centric model이 기존 방법보다 우수할 것으로 기대되는 조건을 충실히 반영합니다.
실세계 평가를 위해, LeRobot 라이브러리와 SO-100 로봇 팔을 사용하여 구현한 다섯 가지 tabletop manipulation task 세트를 도입합니다. 이 task들은 picking, placing, folding, drawer manipulation과 같은 일반적인 가정 내 활동을 반영하도록 설계되었으며, deformable, articulated, rigid 요소를 포함한 다양한 object 특성을 다룹니다. 이러한 실험 설정은 현실적인 noise와 embodiment 제약 조건 하에서 object-centric model의 실질적인 적용 가능성을 검증할 수 있도록 합니다. 모든 환경과 task에 대한 자세한 설명은 Annex D에 제시합니다.
Pre-trained visual models
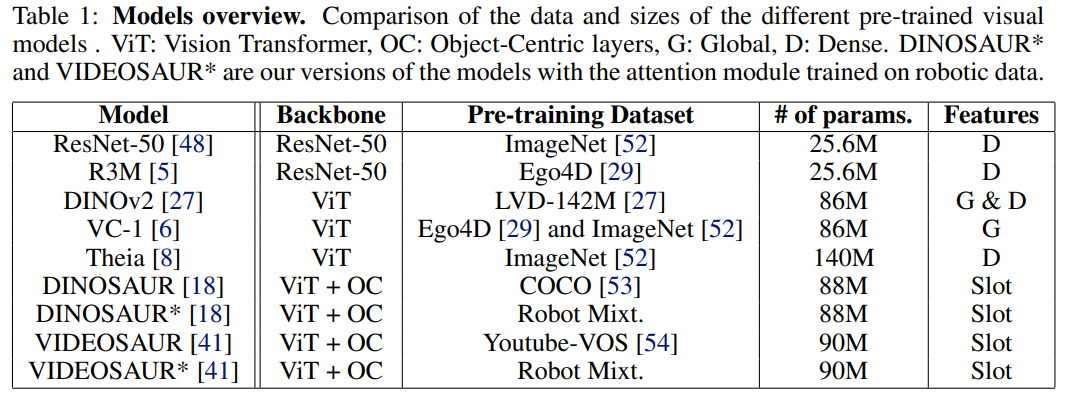
최근 state-of-the-art 평가를 기반으로, 우리는 비교를 위해 7개의 pre-trained visual model을 선정하며, 이는 Table 1에 제시되어 있습니다. 이들 모델은 ResNet 계열과 Vision Transformer 기반 모델을 포함한 다양한 backbone architecture를 포괄하며, supervised learning, self-supervised learning, contrastive learning, distillation 등 다양한 training objective를 사용합니다. 선정된 모든 모델은 각 범주에서 benchmark 평가 기준으로 state-of-the-art 성능을 입증한 모델입니다. 또한 classical global representation과 dense representation뿐만 아니라 object-centric representation까지 포함하여, 폭넓은 feature representation 스펙트럼을 포괄하도록 구성합니다. 각 모델에 대한 추가적인 세부 사항은 Appendix A에 제시합니다.
Robotic pre-training
Object-centric video model은 구조화된 scene decomposition 측면에서 잠재력을 보이지만, 일반적으로 internet-scale in-the-wild video dataset으로 학습되며, 이는 데이터 다양성은 높지만 로봇 조작 환경의 분포와는 불일치하는 경우가 많습니다. 이러한 차이를 해소하고 training data의 다양성을 확장하기 위해, 로봇 video dataset을 활용한 별도의 pretraining 단계를 도입합니다.
다양한 manipulation skill, environment, embodiment를 포괄하는 실세계 로봇 dataset을 수집하고 전처리합니다. 전체 training set은 총 188,000개 이상의 trajectory로 구성되며, WidowX-250 로봇 팔을 사용한 가정용 task demonstration을 포함하는 BridgeData V2, Everyday Robots 로봇 플릿을 활용하여 수백 개의 주방 조작 task를 수집한 대규모 dataset인 Fractal, 그리고 여러 실험실과 설정에서 수행된 자유로운 로봇 상호작용을 포함하는 DROID로부터 수집됩니다. 이 결합된 dataset은 다양한 시점, object 유형, 그리고 조명 조건을 포함하는 풍부한 visual 및 physical 다양성을 제공합니다.
Object-centric model을 로봇 domain에 적응시키기 위해, 우리는 temporal video slice에서 추출한 DINO feature map에 대해 self-supervised reconstruction loss를 적용하여 slot attention module을 학습합니다. 이 접근 방식은 모델이 로봇 조작 dynamics에 기반한 구조적 representation을 학습하도록 합니다. 또한 dataset 구성 방식이 downstream 성능에 미치는 영향을 체계적으로 분석하기 위해, 단일 source dataset으로 학습한 모델과 세 가지 source를 균형 있게 혼합한 dataset(Robot Mixt.)으로 학습한 모델을 비교 평가합니다. 각 dataset의 세부 구성과 이러한 training regime이 generalization 및 policy learning에 미치는 영향에 대해서는 Annex C에서 상세히 설명합니다.
5 Results
본 연구에서는 로봇 조작 policy의 학습과 일반화에서 visual representation이 수행하는 역할을 평가하며, 특히 object-centric representation(OCR)에 초점을 맞추어 dense 및 global 대안과 비교합니다. 본 결과는 section 1에서 제기한 다음 질문들에 답하는 것을 목표로 합니다.
- Q1: OCR은 다른 visual representation에 비해 로봇 policy learning을 더 잘 지원할까?
- Q2: OCR은 distractor, 조명 변화, 새로운 texture와 같은 visual distribution shift 하에서 policy generalization을 향상시킬 수 있을까?
시뮬레이션과 실세계 설정 모두에서 모델을 평가합니다. 시뮬레이션에서는 task당 50회의 rollout을 수행하고, 세 개의 random seed에 대한 평균 성공률을 보고합니다. LeRobot을 사용한 실세계 평가에서는 task당 10회의 rollout을 수행합니다. 모든 policy는 visual encoder를 freeze한 상태에서 학습합니다.
5.1 Q1: Do OCRs improve manipulation policy learning?
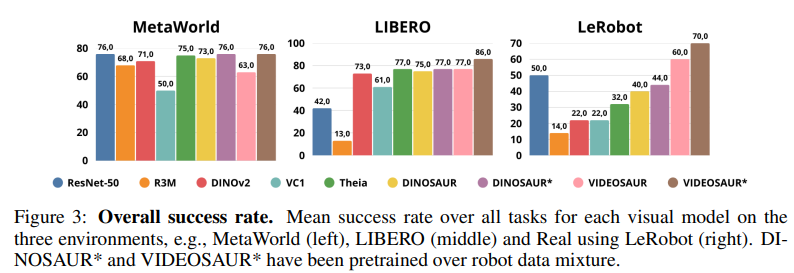
Figure 3은 MetaWorld, LIBERO, 그리고 실세계 benchmark 전반에서의 평균 성공률을 요약합니다. Object-centric model—특히 VIDEOSAUR*—은 일관되게 가장 높은 전체 성능을 달성하며, dense 모델(예: DINOv2, Theia)과 global 모델(예: ResNet-50, VC-1) baseline을 상회합니다.
MetaWorld에서는 VC-1을 제외한 모든 모델이 60% 이상의 성능을 보입니다. VC-1의 낮은 성능은 fine-tuning이 ㅇ벗는 상태에서 domain mismatch에 민감한 MAE 기반 pretraining 때문일 가능성이 큽니다. Objec-centric model은 환경이 단순함에도 불구하고 상위 baseline과 유사한 성능을 봉비니다.
다중 obejct를 포함한 복잡합 scene을 특징으로 하는 LIBERO에서는 OCR이 다른 모든 representation을 명확히 능가함을 보여줍니다. VIDEOSAUR은 최상의 dense 모델인 Theia 대비 +9%의 성능 향상을 보여주며, multi-object interaction을 처리하는 능력을 입증합니다.
LeRobot을 사용한 실세계 설정에서도 OCR은 다시 한 번 다른 모델을 상회합니다. VIDEOSAUR은 최상의 dense baseline이 50%인 것과 비교해 70%의 성공률에 도달합니다. 흥미롭게도 ImageNet으로 pretraining된 가장 단순한 모델인 ResNet-50 역시 경쟁령 있는 성능을 보이는데, 이는 모델의 compact한 크기와 visual pretraining 데이터의 다양성 때문일 가능성이 있습니다.
네 가지 OCR 변형을 비교하면 추가적인 통찰을 얻을 수 있습니다. 첫째, Robotic data를 pretraining에 포함하는 것이 OCR 모델의 성능에 매우 큰 이점을 제공함을 확인합니다. (DINOSAUR* vs DINOSAUR, VIDEOSAUR* vs VIDEOSAUR 비교). 특히 VIDEOSAUR은 MetaWorld, LIBERO, LeRobot 환경에서 각각 13, 11, 10포인트의 평균 성능 향상을 보입니다. 둘째, 동일한 pretraining 데이터를 사용하면서 temporal dynamics 모델링만 추가한 DINOSAUR와 VIDEOSAUR를 비교하면, Figure 3에서 확인할 수 있듯이 temporal dynamics를 고려하는 것이 또 하나의 주요 성능 향상 요인임을 알 수 있습니다. 이는 LIBERO와 LeRobot 환경에서 DINOSAUR 대비 각각 +9, +26포인트의 개선을 가져옵니다. 반면 VIDEOSAUR와 DINOSAUR는 pretraining 데이터가 서로 다르므로 동일한 결론을 내리기 어렵습니다.이는 특히 MetaWorld VIDERSAUR가 DINOSAUR보다 성능이 낮아지는 현상을 설명할 수 있습니다. 구체적으로, robotic data는 고정된 카메라와 일관된 motion pattern을 갖는 구조화된 scene을 제공하는데, 이는 움직이는 카메라와 예측하기 어려운 scene의 변화를 포함하는 in-the-wild 데이터로 학습된 원래의 VIDEOSAUR와 대조적이기 떄문입니다. 또한, visual domain 자체도 크게 다릅니다.
종합하면, Q1에 대한 결과는 object -centric model이 효과적일 뿐 아니라 domain 전반에 걸쳐 확장 가능하며, 구조화된 시뮬레이션 task와 noisy한 실세계 환경 모두에서 성능 이점을 제공함을 확인합니다.
5.2 Q2: Do OCRs enhance generalization under visual distribution shifts?

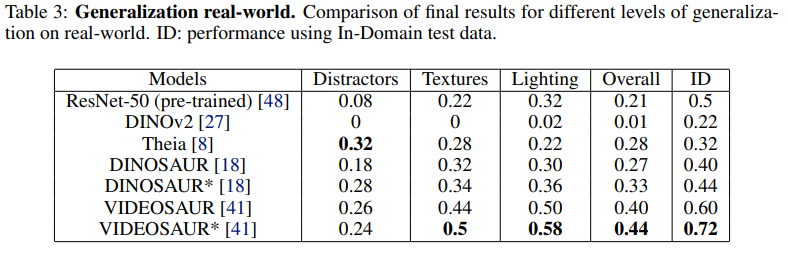
새로운 distractor, 보지못한 texture, 조명 변화 등 out-of-distribution 조건에 대한 generalization을 평가합니다. Table 2와 Table 3는 이러한 시나리오에서의 성공률을 보고합니다.
MetaWorld에서는 Table 2에서 확인할 수 있듯이, DINOv2와 Theia와 같은 dense 모델이 평균적으로 ResNet보다 우수한 성능을 보이며 이는 기존 연구 결과와 일치합니다. 그러나 OCR—특히 VIDEOSAUR*—은 texture 및 조명 변화 하에서 모든 baseline을 일관되게 상회합니다. 주목할 점은 distractor 시나리오에서는 Theia가 가장 우수한 성능을 보이는데, 이는 CLIP 기반 text–image alignment가 irrelevant patch를 무시하는 데 도움을 주기 때문으로 보입니다. 그러나 Theia는 다른 시나리오에서 성능이 급격히 하락하는 반면, OCR은 훨씬 더 강건한 모습을 보입니다.
실세계 평가 결과(Table 3)에서도 VIDEOSAUR*는 texture 및 조명 변화 하에서 성공률 감소가 가장 적어 강한 강건성을 보입니다. Theia는 distractor 시나리오에서는 다시 가장 좋은 성능을 보이지만, 다른 shift에서는 실패합니다. ResNet-50은 texture와 조명 변화에 대해 예상외로 좋은 회복력을 보이지만, 모든 shift 전반에서 일관된 성능을 유지하지는 못합니다.
요약하면, Q2에 대한 결과는 object-centric representation이 다양한 distribution shift, 특히 low-level appearance를 교란하는 변화에 대해 더 잘 일반화함을 보여줍니다. 이러한 강건성은 OCR이 task-irrelevant한 background를 걸러내고 object-level 구조에 집중할 수 있는 능력에서 비롯된 것으로 보입니다.
6 Conclusion
본 연구에서는 로봇 조작 policy의 generalization과 robustness를 향상시키는 데 있어 OCR의 잠재력을 분석합니다. 기존의 visual encoder와 달리, OCR 기반 모델은 물리적 상호작용의 구조적 특성을 더 잘 반영하는 inductive bias를 도입하며, 그 결과 시뮬레이션과 실세계에 걸친 다양한 조작 task 전반에서 일관되게 우수한 성능을 보입니다.
본 결과는 로봇 에이전트의 효율성과 일반화를 동시에 진전시키기 위해 visual representation을 재고하느 것이 중요함을 강조합니다. 즉, flat한 pixel-level feature에서 벗어나 보다 구조화된 object-based encoding으로 이동해야 함을 시사합니다. Object-centric bias를 활용함으로 써 low-level visual input과 high-level symbolic reasoning 사이의 간극을 메울 수 있으며, 이를 통해 로봇이 주변 환경을 더 잘 이해하고 상호작용할 수 있도록 합니다.본 연구에서는 OCR이 sim-to-real-gap을 해소하고 확장 가능하며, 일반화 가능한 로봇 제어를 달성하기 위한 유망한 기반을 제공한다고 판단합니다. 향후 연구에서는 OCR을 다양한 architecture, multimodal input, 그리고 self-supervised learning framework와 더 깊이 통합하여 확장성과 downstream 활용도를 극대화하는 방향을 탐구해야 합니다.
7 Limitations

본 연구에서는 광범위하고 철저한 실험을 수행하고자 노력하였으나, 몇 가지 한계가 존재하며 이는 향후 연구에서 다루어져야 합니다.
첫째, 본 연구에서 사용한 object-centric 방법은 특정 object에 본질적으로 binding되지 않으며, semantic grounding이 부족합니다. Figure 7에 나타난 바와 같이, 일부 slot은 의미 있는 semantic content를 포착하지 못한 채 background 영역에 할당되며, 일부 failure case에서는 slot이 distractor를 포착하는 현상도 관찰됩니다. 이러한 한계는 affordance와 같은 semantic 정보를 통합하는 것이 object-centric representation의 해석 가능성과 실용성을 향상시킬 수 있음을 시사합니다. 또한 이는 Theia에서 관찰된 결과와 같이, distractor가 존재하는 상황에서 OCR의 generalization 능력을 개선하는 하나의 경로를 제공할 수 있습니다.
둘째, 본 연구는 로봇 dynamics와의 alignment를 고려하지 않습니다. 본 연구에서는 이러한 요소를 통합하는 것이 특히 최근 연구에서 강조된 바와 같이 실제 적용 가능성을 크게 향상시킬 수 있다고 판단합니다. 향후 연구에서는 object-centric model을 로봇 시스템과 더 잘 정렬시키기 위한 이 방향을 탐구해야 합니다.
마지막으로, 본 연구의 범위는 pre-training에 사용된 모델과 dataset의 규모에 의해 제한되었습니다. 더 큰 모델과 보다 다양한 dataset을 포함하도록 확장한다면, 보다 강건하고 일반화 가능한 결과를 도출할 수 있을 것으로 기대합니다. 이는 기존 연구에서 수행된 접근을 확장하는 방향이며, 모델의 능력과 한계를 보다 철저히 평가할 수 있게 할 것입니다.